DigitalOcean推出了专为AI工作负载设计的AI原生云,整合了五个层次的服务,支持高性能推理,提供GPU和CPU资源,优化模型路由,降低成本。用户可以在同一环境中运行多个模型,提升效率,减少集成复杂性,旨在满足AI开发者的需求,促进更快的开发和部署。
v0.11.0版本标志着vLLM完全迁移至V1引擎架构,得益于1969名贡献者的支持。该版本优化了高性能LLM推理,提升了每个H200 GPU的吞吐量至2.2k tokens/s。
百度推出FastDeploy 2.0,支持高效部署文心4.5等大模型,具备易用性、高性能推理和多硬件兼容性。通过量化技术降低资源需求,提升推理性能,助力企业和研究者应用大模型。
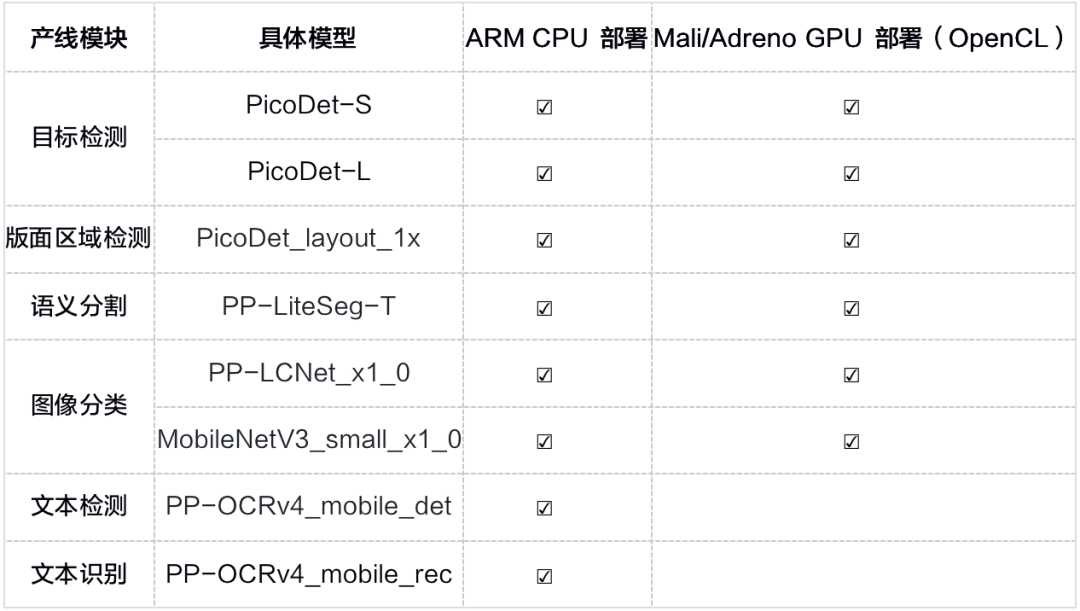
PaddleX 3.0-beta1版本在AI模型部署方面进行了重要升级,提供高性能推理、服务化部署和端侧部署解决方案,以满足多样化的应用需求。高性能推理插件提升了模型推理速度,服务化部署增强了系统灵活性,端侧部署支持在用户设备上运行,确保快速响应和隐私保护。
飞桨于2023年12月推出低代码开发工具PaddleX 3.0-beta1,集成200多个模型,支持一键调用和高性能推理。新版本提供多种部署方案,包括本地推理、服务化部署和端侧部署,兼容多种硬件,简化了模型训练和集成流程,降低了开发门槛,适合不同应用场景。
完成下面两步后,将自动完成登录并继续当前操作。