

如何理解AI陪聊软件原理?哪些场景适合AI陪聊软件
实时互动网
·
LangGraph 是如何让LLM产生确定性输出的?
luozhiyun`s Blog 我的技术分享
·
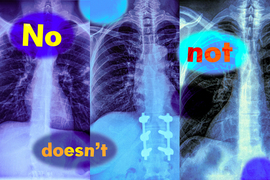
研究表明视觉语言模型无法处理包含否定词的查询
MIT News - Artificial intelligence
·

实用的人机协作代理:实操指南
DEV Community
·


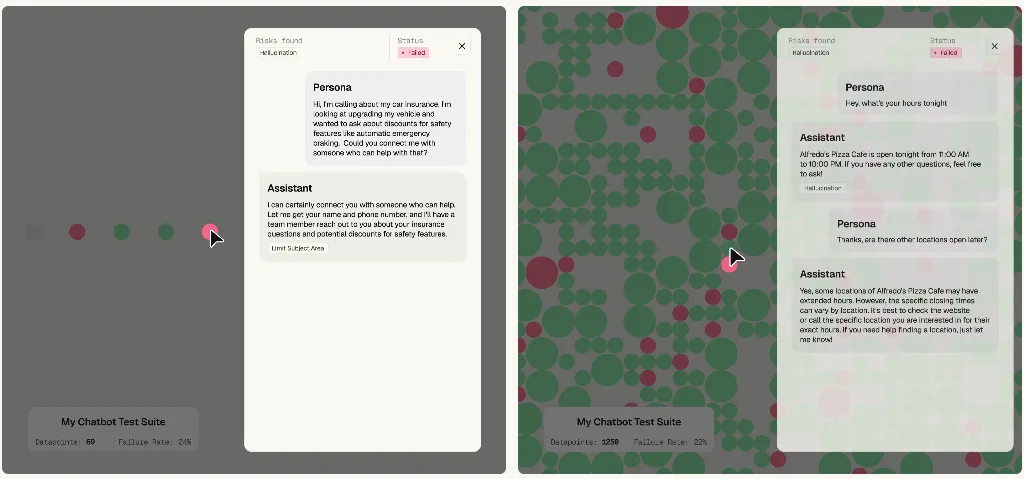
基于变异分析和多样化测试数据的高信心测试
DEV Community
·
