微软在2025年发布的.NET 8引入了AOT编译、PGO动态优化和AVX-512支持等性能优化技术,显著提升应用性能。AOT编译加快启动速度,PGO优化热点代码,AVX-512支持并行计算,适用于图像处理和金融分析等场景。此外,新API和C# 12特性提升了开发效率,强调根据业务需求选择优化策略。
本文介绍如何在纯Rust中编写SIMD加速代码,强调AMD Zen 5 CPU对AVX-512指令的支持。SIMD工作流程包括加载、计算和存储,减少内存访问至关重要。作者期待可移植的SIMD特性进入稳定版,以简化跨平台开发。使用SIMD可以显著提升性能,而Rust使实现过程更加简单。
AMD Zen 5 CPU在性能上取得突破,支持AVX-512指令,提升了SIMD编程效率。使用纯Rust编写的SIMD代码可显著提升性能,适用于多平台。Servo浏览器引擎新增多窗口和代理支持,并改进了开发者工具和Web功能。
OpenCV 4.13 于新年夜发布,增强了计算机视觉功能,优化了 Windows on ARM 性能,支持 AVX-512 指令集,新增图像处理模块,改进了 JavaScript、Python 和 Java 绑定,并支持 NVIDIA CUDA 13.0。
在Linux年度维护者峰会上,Rust项目被正式纳入内核核心部分。Ralf Jung在Scala大会上探讨了Rust的不安全特性及其重要性。Trifecta Tech团队在Miri中模拟AVX-512指令集,解决了zlib-rs项目的测试问题,提升了跨平台测试能力。Bevy游戏引擎监测性能指标,发现了回归问题。
FFmpeg 8.0 发布,新增 OpenAI Whisper 语音识别过滤器,改进 Vulkan 视频处理,优化 CPU 性能,支持多种解码器和编码器,提升 AVX-512 性能。
FFmpeg 开发人员通过优化汇编代码,提升了 Bwdif 去隔行扫描视频滤镜的性能,使用 AVX-512 时速度比基本 C 代码快 23~28 倍。新实现支持较新的英特尔和 AMD 处理器,但对 Skylake 处理器有限制。该优化将在 FFmpeg 8.0 中发布。
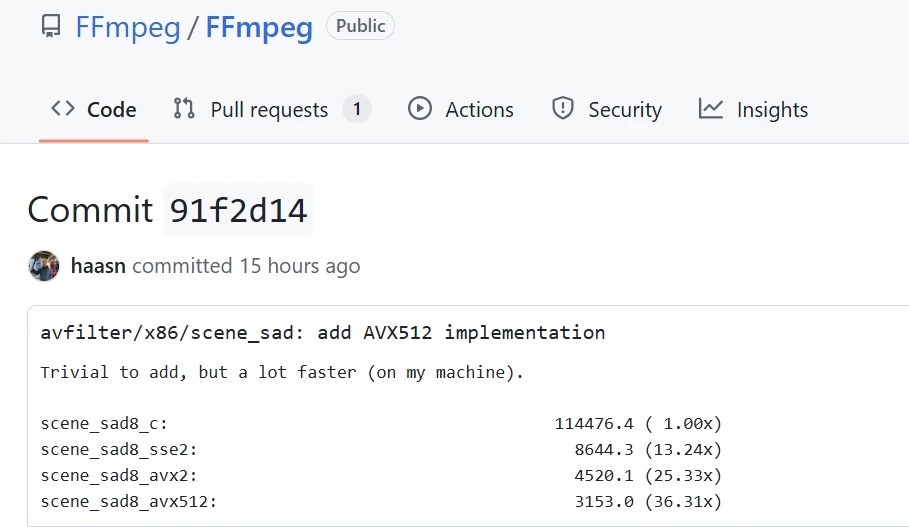
FFmpeg 最近合并了针对 AVX-512 和 AVX2 的手工优化代码,显著提升了性能。基准测试显示,使用 AVX-512 的 avfilter scene_sad 速度是普通 C 代码的 36.31 倍,AVX2 为 25 倍。高位深度版本在 AMD Zen 4/Zen 5 和 Intel Xeon 处理器上表现尤为出色。
这篇文章探讨了SIMD编程的设计模式,强调数据布局的重要性,提出SoA(结构数组)相较于AoS(数组结构)的优势。介绍了无分支条件赋值的mask + blend方法,以及pshufb指令在字节查表和前缀和实现中的应用。最后,讨论了AVX-512的新特性和跨平台的SIMD策略,建议使用Google Highway库进行跨平台开发。
2025年2月18日,FFmpeg合并了AVX-512优化代码,性能提升至普通C代码的18倍,AVX2为10.98倍。新代码用于将UYVY转换为YUV422,适用于支持AVX-512的AMD Zen 4和Zen 5 CPU。
作者开发了一种基于AVX-512指令的短语搜索算法,速度比Meilisearch快1600倍,历时七个月。文章讨论了汇编语言、性能分析和算法优化,展示了极限性能提升的潜力。
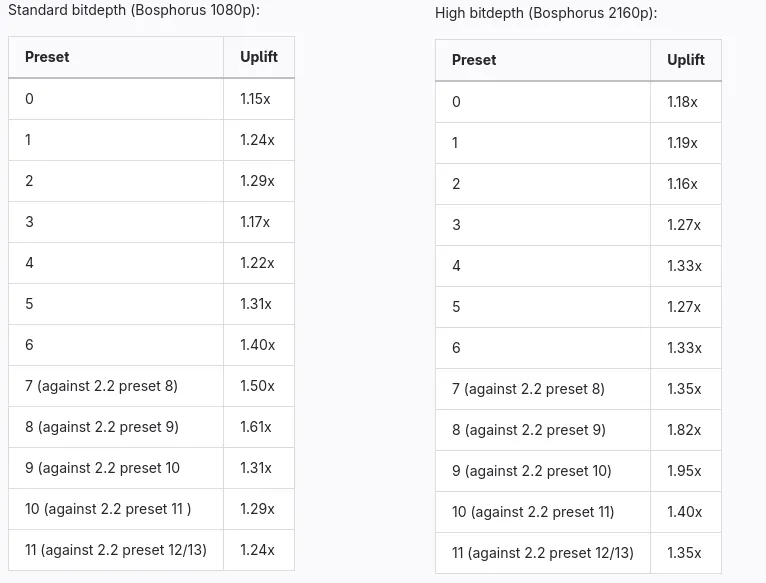
SVT-AV1 2.3 发布,提升了编码器性能,新增快速解码模式,编码周期减少 25-50%。改进高分辨率设置,支持 AVX512 加速,整体性能显著提升。
本文介绍了.NET7和.NET8中的stackalloc分配和清零优化技术,通过使用ymm0和zmm0寄存器一次性清零32或64个字节,大大提高了性能。测试结果显示,相对于.NET7,.NET8的性能提升了两到三倍。作者还提到了AVX512的zmm0寄存器可以一次性清零64个字节的优化方式。
.NET 8已正式发布,带来了数千个性能改进。它引入了一种名为Profile-Guided Optimization (PGO)的新代码生成器,可以根据实际使用情况优化代码,提高应用程序性能高达20%。现在支持AVX-512指令集,允许对512位数据向量进行并行操作。.NET 8还增强了容器功能,提供了本地Ahead-of-Time (AoT)编译,集成了AI能力,支持用于构建全栈Web应用程序的Blazor,并通过.NET MAUI和C# 12功能改进了开发人员体验。其他改进包括反射改进、配置绑定源生成器、时间抽象、UTF8改进、SHA-3的加密支持以及基于流的ZipFile方法。
英特尔发布了使用AVX-512的超快排序库x86-simd-sort 3.0,可提高Numpy中数据类型的排序速度。OpenJDK已将该加速排序代码的修改版本合并到参考JDK代码库中,32位数据排序速度提高了15倍,64位数据排序速度提高了约7倍。
该文章介绍了现代软件对Unicode标准的依赖,以及在内存中使用UTF-8或UTF-16表示Unicode字符串的情况。同时,介绍了simdutf库的用途和性能提升,该库支持多种指令集,包括AVX-512,可以加速字符串转码。文章还提到了该库提供的快速Unicode函数,例如验证和转码等。最后,文章强调了该库的高性能和广泛的测试和基准。
完成下面两步后,将自动完成登录并继续当前操作。