

Jina ColBERT v2:用于嵌入和重排序的多语言后期交互检索器
Jina AI
·
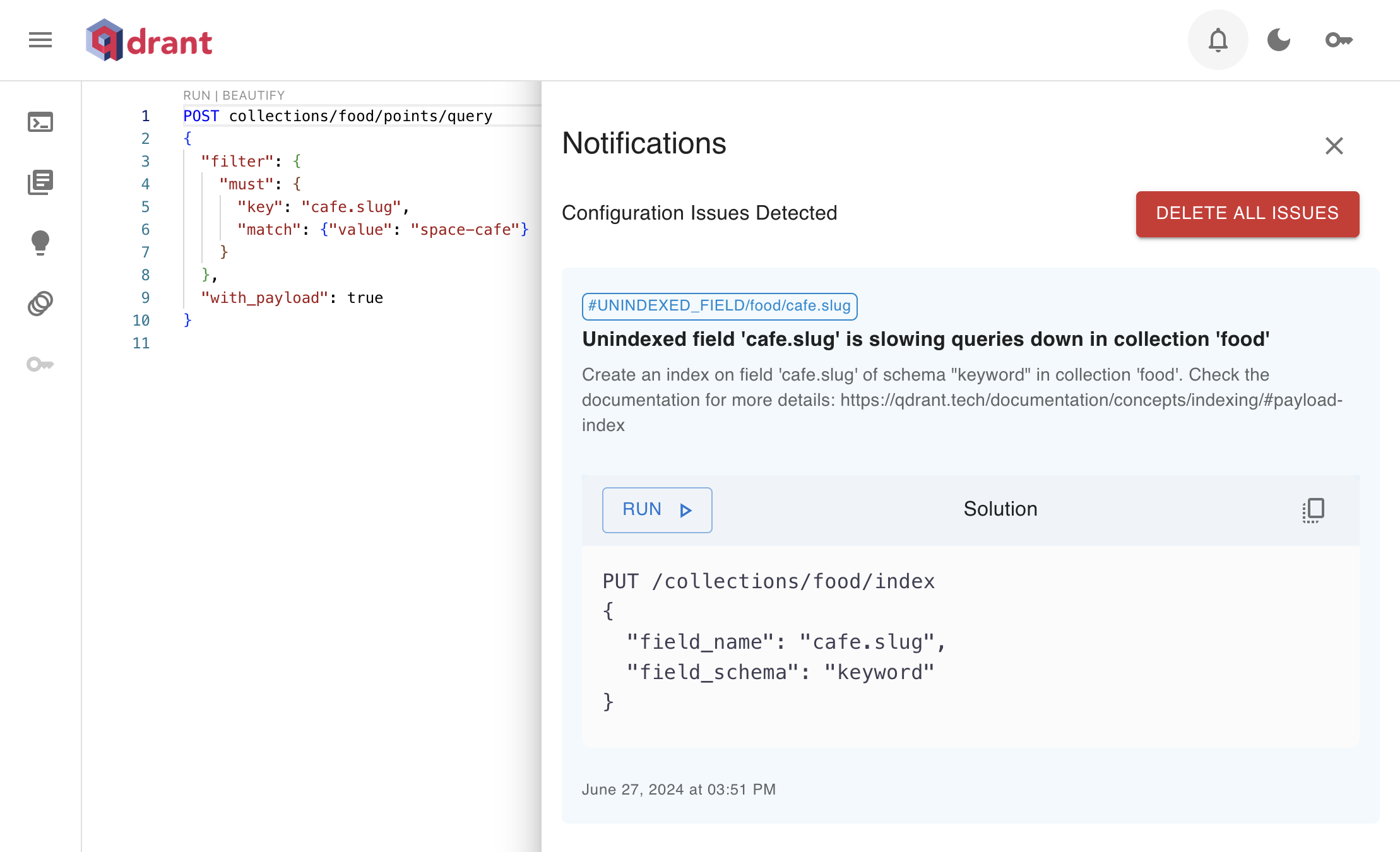
Qdrant 1.10 - 统一查询、内置IDF及ColBERT支持
Qdrant - Vector Database
·

Working with ColBERT
Qdrant - Vector Database
·
