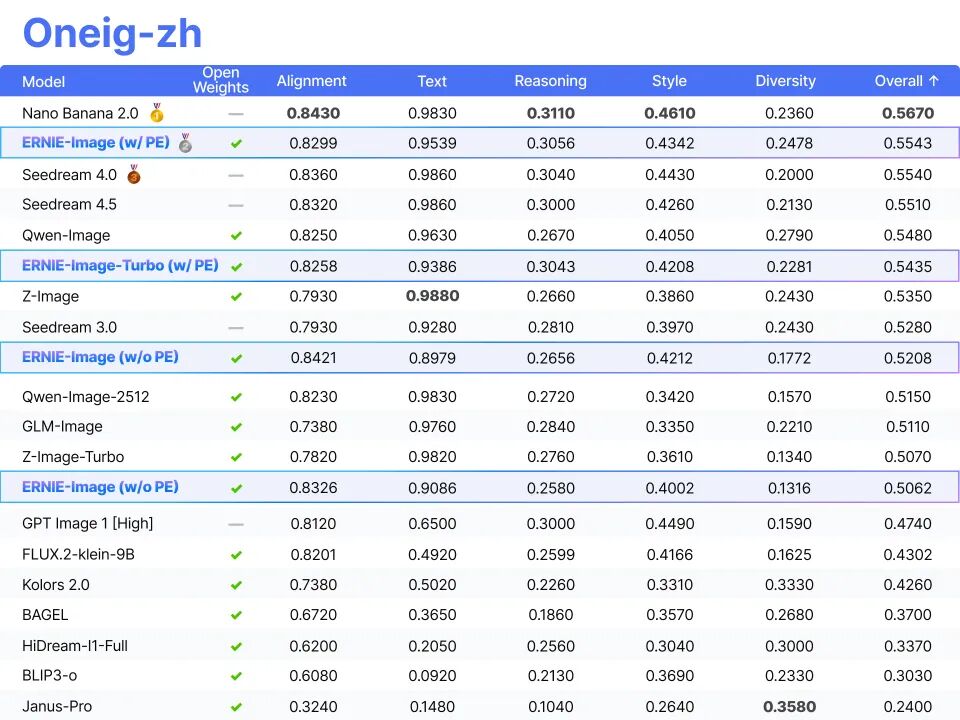
ERNIE-Image是百度文心团队开发的开源文生图模型,基于8B参数的Diffusion Transformer架构,支持多种视觉风格,适合海报和漫画等内容生产。该模型在Hugging Face上开源,支持多语言生成,降低了创作门槛,鼓励用户参与创作。
视频生成领域取得显著进展,但缺乏系统化开发指南。本文提出STIV,一种结合Diffusion Transformer架构的文本图像条件视频生成方法,支持文本到视频和图像到视频任务。STIV在多项任务中表现优异,为构建先进视频生成模型提供了透明方案,推动未来研究。
加州大学伯克利分校等机构联合制作的《猫和老鼠》AI短片引发关注。该短片利用测试时训练(TTT)层生成,展示了复杂的动态故事。研究者使用预训练的Diffusion Transformer生成了一分钟的连贯视频,展示了AI在动画创作中的新进展。
360AI推出了新一代高效可控生成框架RelaCtrl,参数量减少85%,性能超越OminiControl。该框架优化了Diffusion Transformer的控制信号集成,提升了计算资源分配效率,实验结果显示生成质量和控制精度均表现优异。
新加坡国立大学的MakeAnything项目利用Diffusion Transformer和非对称LoRA技术,实现高质量的程序化序列生成,解决了步骤逻辑、外观一致性和数据瓶颈等问题,展现出良好的泛化能力。
文章讨论了对π0开源项目的期待与遗憾,分析了OpenVLA和CogACT的源码,重点介绍了动作预测模块的实现,包括ActionTokenizer类的功能和Diffusion Transformer的架构。通过对比不同模型,探讨如何改进VLA以接近π0的思路。
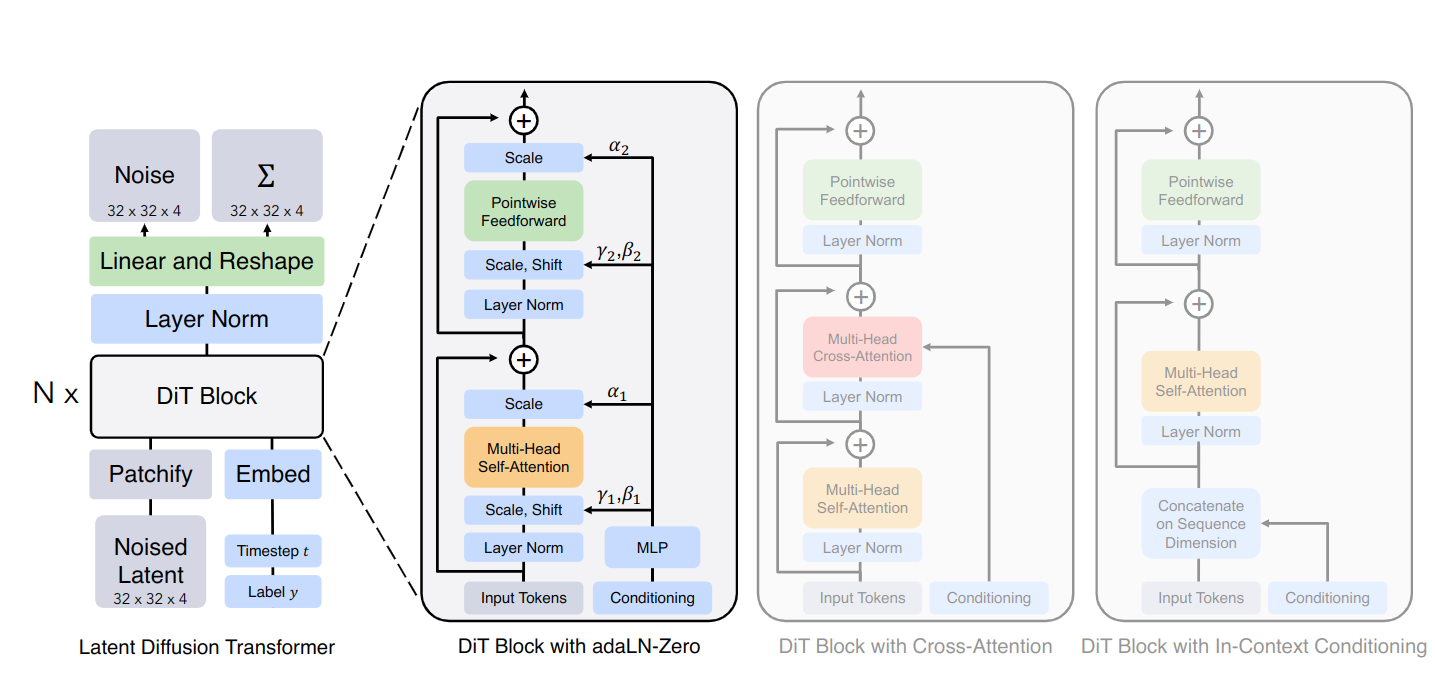
本文介绍了Diffusion Transformer(DiT),一种用Transformer架构替代U-Net的神经网络,结合了视觉Transformer和扩散模型的优点。DiT在视频生成中调整模型结构以支持不同分辨率,并引入时间维度以保持一致性。研究者还探讨了类似的U-ViT架构,强调了Transformer在扩散模型中的潜力。
本文探讨了用ViT替代DDPM中的UNet,提出了Diffusion Transformer-DiT模型。作者训练了四种不同大小的DiT模型,研究了补丁大小、变压器架构和模型规模。模型通过处理补丁序列进行操作,并在设计中加入去噪步数和类别标签,最终输出噪声预测和协方差。
完成下面两步后,将自动完成登录并继续当前操作。