An overview of DML support for JSON Relational Duality Views introduced in version 9.4.
我们采访了Netmarble Monster工作室的创始人兼首席执行官Ken Kim,深入探访由UE5开发的跨平台收集型动作冒险游戏《MONGIL: STAR DIVE》的最新进展。快来听听他怎么说。
Docker镜像由不可变层构成,每层对应Dockerfile指令的变化。大型AI镜像因包含大量库和基础操作系统组件而显得臃肿。使用docker history和dive工具可以诊断和优化镜像,减少体积,提高效率,降低云成本,增强安全性。
I'm sharing the slides and transcript from my talk about the PostgreSQL Europe Diversity Task Force at PostgreSQL Development Conference 2025. It's an extended version of the 5 minute...
We're ready to open registrations for the first ever Search Central Live Deep Dive, a 3-day event that will be held in Bangkok, Thailand this year on July 23-25!
For users of HeatWave Service, the maintenance process can sometimes feel like a black box. What does it entail? How does it differ from version upgrades? When and how are updates applied? With...
Dive是一款适用于Windows和Linux的桌面应用,支持多种LLM,简化MCP服务器安装,提供实时工具调用和高效系统集成。更新内容包括多模型支持、消息编辑、自动更新和后台运行,提升用户体验和性能。
本文探讨了构建容器镜像的工具和方法,介绍了在Gitlab CI和AWS ECR中使用Buildah、Dive和Skopeo等工具进行持续交付的流程。这些工具能够高效构建、测试和推广容器镜像,无需依赖Docker守护进程,适合在Kubernetes等敏感环境中使用。
Deep dive on going from Vue to Htmx in a large-scale production app
FIPS compliance is crucial for numerous MySQL deployments, especially within government agencies and organizations subject to regulatory mandates. The alignment of FIPS 140-3 with ISO/IEC 19790...
Deep Dive into LLMs like ChatGPT
我们的团队开发了一个名为Dive的开源平台,支持多种LLM,兼容Windows、Mac和Linux,采用MIT许可证,支持模型上下文协议,用户可扩展功能。
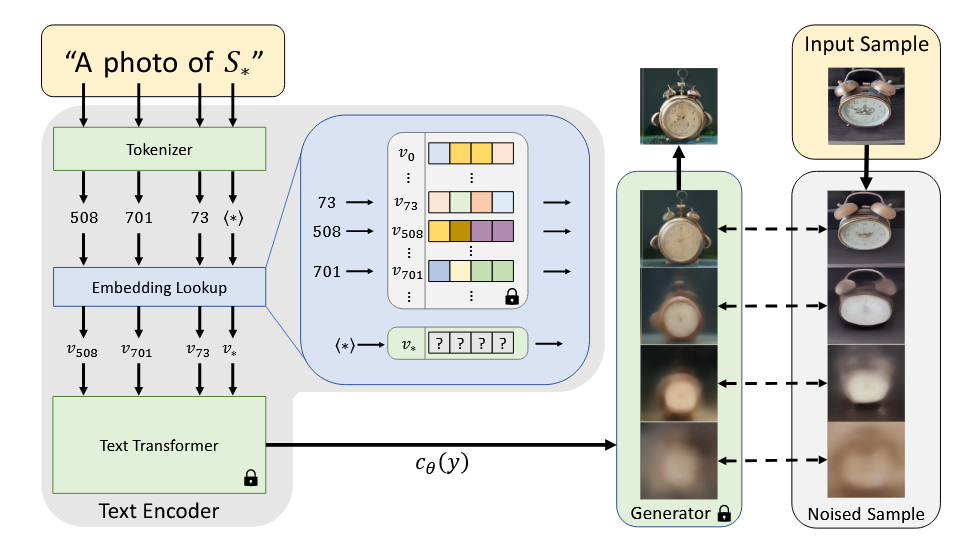
文生图和图生图技术发展了多种微调方法,如Textual Inversion和DreamBooth。LoRA技术通过调整计算模块提高微调效率,结合不同方法可获得更佳效果。尽管新概念和个性化生成面临挑战,但优化嵌入向量可以解决这些问题。
本研究探讨了多模态大型语言模型(MLLMs)在医疗和自主驾驶领域的不确定性校准挑战。通过构建IDK数据集评估模型在面对未知时的表现,发现MLLMs倾向于给出答案而非承认不确定性。研究提出了温度缩放和迭代提示优化等校准技术,以提高模型的可靠性。
本研究探讨视觉语言模型(VLMs)处理视觉信息的机制。分析表明,查询令牌有效存储全局图像信息,中层对跨模态信息流的影响显著,细粒度视觉属性和对象细节通过空间定位从图像中提取。这些发现为提升VLMs的视觉处理效率提供了新思路。
本研究探讨了如何预测足球反击的成功率,采用性别特定的图神经网络模型,结果表明这些模型在预测成功率方面优于性别模糊模型。同时,研究提供了开源数据和代码,方便读者进行复制和改进。
本研究提出DAMRO策略,以减少大规模视觉语言模型中的对象幻觉问题。通过分析注意力机制,发现现有模型在注意力分配上存在缺陷,导致冗余信息被过度强调。DAMRO通过过滤高注意力异常标记,显著提升了模型的准确性和可靠性。
本文介绍了VisualComet框架,旨在预测图像中的事件和人物意图,并建立了一个包含140万个文本描述和图像的数据集。研究探讨了多模态模型在视觉常识生成中的应用,提出了新的预训练任务以提升性能,强调了数据多样性对生成文本的影响,并提出了结合视觉-语言模型的细粒度常识提取任务。
本文综述了图形领域中的OOD(Out-Of-Distribution)适应方法,分类现有技术并探讨未来研究方向。提出了GOOD-D和GLIDER框架,改进了无监督图对比学习的异分布推广性。同时,研究揭示了图神经网络中的潜在偏差,并提出了基于因果关系的StableGNN框架,显著提高了模型的泛化性能。
完成下面两步后,将自动完成登录并继续当前操作。