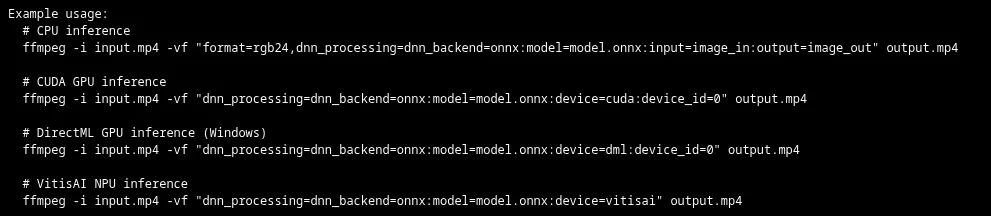
AMD 工程师为 FFmpeg 提供了 ONNX Runtime 后端,支持深度神经网络 (DNN) 滤镜,允许在视频处理过程中使用 AI 模型,兼容多种 GPU 和 NPU 平台,包括 NVIDIA CUDA 和 AMD Ryzen AI NPU,增强了 FFmpeg 的视频处理能力。
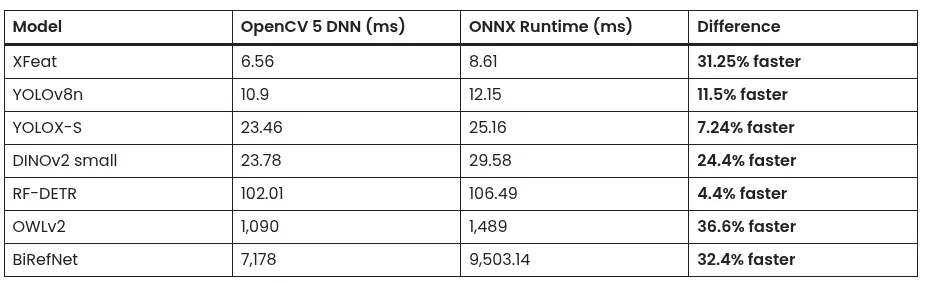
OpenCV 5.0于2026年6月6日发布,新增深度神经网络引擎重写、80% ONNX覆盖率和内置大型语言模型支持等功能,并针对多种硬件进行了优化,计划实现原生GPU支持。
Triton是一种基于Python的并行编程语言和编译器,旨在高效编写自定义DNN计算内核,并在现代GPU上运行。它支持多种指针类型和边界检查选项,能够存储数据张量。
Triton是一种基于Python的并行编程语言和编译器,旨在高效编写自定义DNN计算内核,并在现代GPU上实现最大吞吐量。它支持加载数据张量以及多种指针类型和参数选项。
Triton 是一种基于 Python 的并行编程语言和编译器,专为高效编写 DNN 计算内核而设计,能够在现代 GPU 上运行,支持张量连接和广播,张量大小需为 2 的幂。
Triton 是一种基于 Python 的并行编程语言和编译器,旨在高效编写自定义 DNN 计算内核,以实现现代 GPU 的最大吞吐量。
机器之心数据服务现已上线,提供高效稳定的数据获取服务,简化数据爬取流程。
Triton 是一种基于 Python 的并行编程语言和编译器,旨在高效编写自定义 DNN 计算内核,并在现代 GPU 上运行。其核心数据结构为张量,支持多种操作和函数,简化编程过程。
本研究解决了多租户DNN应用中共享缓存对性能的影响不足的问题。提出了一种名为CaMDN的架构调度协同设计,通过支持模型专属的NPU控制区域,有效消除缓存争用,并通过动态分配算法提高缓存利用率。研究发现,CaMDN平均减少了33.4%的内存访问次数,模型加速提升可达2.56倍。
Triton 是一种基于 Python 的并行编程语言和编译器,旨在高效编写 DNN 计算内核,并在现代 GPU 上实现最大吞吐量。它提供了 @triton.heuristics 装饰器,用于指定元参数值的计算方法。
Triton 是一种基于 Python 的并行编程语言和编译器,专为高效编写自定义 DNN 计算内核而设计,支持现代 GPU 硬件。其核心数据结构为 N 维数组 tensor,并提供多种操作函数。
Triton 是一种基于 Python 的并行编程语言和编译器,旨在高效编写 DNN 计算内核并在现代 GPU 上运行。它提供 @triton.heuristics 装饰器,用于在自动调优不适用时指定元参数值的计算方法。
Triton 是一种基于 Python 的并行编程语言和编译器,旨在高效编写自定义 DNN 计算内核,并在现代 GPU 上实现最大吞吐量。它具备自动调优功能,允许用户通过配置参数优化内核性能。
Triton是一种基于Python的并行编程语言,专为高效编写DNN计算内核并在现代GPU上运行而设计。本文介绍了支持FP16和FP8数据类型的矩阵乘法持久化内核实现,并提供多种矩阵乘法方法,用户可通过命令行参数灵活指定矩阵维度和迭代步骤。
Triton 是一种基于 Python 的编程语言和编译器,专为高效编写 DNN 计算内核而设计,能够在现代 GPU 上运行,支持分组 GEMM 内核,并通过静态调度实现高吞吐量。
本文介绍了一种基于SCRFD的卡证检测与矫正模型,旨在自动提取卡证信息以提高OCR准确率。该模型通过合成数据进行训练,能够检测和矫正各种国际卡证,去除背景,便于后续处理。
该方案为百度网盘AI大赛表格检测的第二名方案,采用ppyoloe-plus-x进行边界框检测,使用DBNet进行语义分割,并通过PP-LCNet预测表格方向,实现高效的表格检测与识别。
该算法为百度网盘AI大赛表格检测的第二名方案,包含表格边界框检测、分割和方向识别。使用ppyoloe-plus-x进行边界框预测,DBNet进行语义分割,PP-LCNet预测表格方向,代码采用C#和OpenCvSharp实现。
本研究解决了传统向量量化技术在DNN压缩中造成显著精度损失的问题。提出了一种新方法MVQ,通过N:M剪枝重要权重并利用掩蔽k-means算法最小化向量聚类误差,从而更好地保留重要权重。实验结果表明,MVQ在可比压缩比下超越了传统方法,显著提高了能源效率。
Triton 是一种基于 Python 的并行编程语言和编译器,旨在高效编写 DNN 计算内核并在 GPU 上运行。它支持调用外部库函数,如 libdevice 库中的反正弦函数,并能自动选择合适的数据类型,简化计算过程。
完成下面两步后,将自动完成登录并继续当前操作。