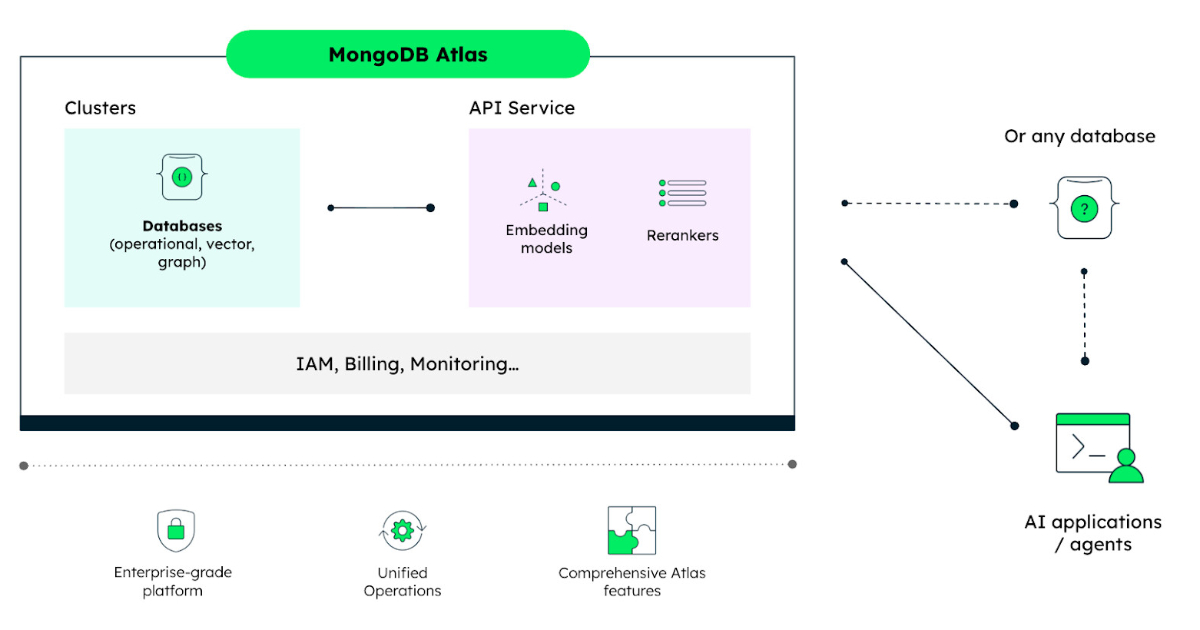
MongoDB在Atlas上推出了Embedding和Reranking API,简化了AI检索系统的构建,支持多种数据库,适用于语义搜索和AI助手,提升操作效率。同时发布的Voyage 4系列模型增强了文本和地理分析功能,支持多种嵌入维度。
苹果推出开源工具Embedding Atlas,旨在交互式可视化大规模嵌入数据。该平台支持浏览器本地计算,确保数据隐私,并提供自动聚类和标签功能,便于高维数据分析。用户可通过Python包和npm库集成,适用于多种开发场景,促进数据科学与前端开发结合。
Embedding Atlas是一款可扩展的交互式可视化工具,旨在简化大规模嵌入数据的交互。它结合现代网络技术和先进算法,提供快速的数据分析体验。与其他工具相比,Embedding Atlas具有独特功能,降低了使用门槛,并支持开源,促进未来的嵌入分析工作。
Meta于2020年提出的RAG框架提升了大语言模型的准确性。InfiniFlow开源的RAGFlow引擎基于深度文档理解,简化了RAG系统的构建流程,支持快速搭建知识库和智能问答系统。
Meta于2020年提出的RAG框架提升了大语言模型的准确性。InfiniFlow开源的RAGFlow引擎解决了文档解析问题,并提供了预构建工作流程,便于快速搭建RAG系统。
Meta于2020年提出的RAG框架提升了大语言模型的准确性。InfiniFlow开源了RAGFlow引擎,解决了文档解析难题,并提供预构建工作流程,方便用户快速搭建RAG系统。
Meta于2020年提出的RAG框架提升了大语言模型的输出准确性。InfiniFlow开源的RAGFlow引擎基于深度文档理解,简化了RAG系统的构建流程,使用户能够快速搭建智能问答系统。
Meta于2020年提出的RAG框架提升了大型语言模型的输出准确性。InfiniFlow开源的RAGFlow引擎基于深度文档理解,简化了RAG系统的构建流程,使用户能够快速搭建智能问答系统。
Meta于2020年提出的RAG框架提高了大语言模型的输出准确性。InfiniFlow开源的RAGFlow引擎基于深度文档理解,简化了RAG系统的构建流程,支持快速搭建本地知识库和智能问答系统。
Meta于2020年提出的RAG框架提高了大语言模型的输出准确性。InfiniFlow开源的RAGFlow引擎基于深度文档理解,简化了RAG系统的构建流程,使用户能够快速搭建智能问答系统。
Meta于2020年提出的RAG框架提高了大语言模型的输出准确性。InfiniFlow开源的RAGFlow引擎基于深度文档理解,简化了RAG系统的构建流程,支持快速搭建知识库和智能问答系统。
RAG(检索增强生成)结合大型语言模型与外部知识源,提高对话AI的准确性与相关性。本文介绍如何在Python中使用LangChain和Zilliz Cloud等组件构建RAG聊天机器人,包括安装、设置和优化技巧,实现基于自定义知识库的问答功能。
企业在应用大模型时需关注知识安全,通过预训练、Embedding、微调和RAG等方法有效灌输知识。在评估技术路径时,应考虑数据需求、专业深度和实时性。建议中小企业停留在Embedding阶段,重视数据治理和风险防控,避免盲目追求技术,关注场景价值。
RAG(检索增强生成)结合大型语言模型与外部知识源,提升对话AI的准确性与相关性。本文介绍如何利用LangChain、Milvus和Claude 3构建RAG聊天机器人,并提供优化建议与成本计算工具,以帮助开发高效的AI应用。
本文介绍了Embedding技术在自然语言处理中的应用与发展,强调其在机器学习和深度学习中的重要性。Embedding通过向量表示对象,推动了Word Embedding和Item Embedding等技术的进步,提高了分类和问答等任务的效率。动态词嵌入模型如BERT和GPT解决了一词多义问题,促进了NLP领域的发展。
本文介绍了Embedding技术在自然语言处理中的应用与发展。Embedding通过向量表示对象,已从Word Embedding扩展到多种形式,如Item和Graph,提升了机器学习和深度学习的效率。动态词嵌入模型如BERT和GPT解决了一词多义问题,推动了NLP性能的提升。
Apache SeaTunnel中的Embedding转换插件将文本数据转换为向量表示,支持多种模型提供者和API集成。本文介绍了插件的配置选项,如模型提供者、API密钥和自定义配置,旨在帮助读者在实际项目中应用这些概念。
本研究提出了一种新颖的完全双曲模型,克服了现有双曲旋转模型在知识图谱嵌入中的局限性。实验结果表明,该模型在知识图谱完成基准测试中表现优越。
在医疗行业,医生与药厂需有效沟通专业术语。随着医学文献增多,快速匹配治疗方案变得困难。客户希望通过大模型优化文献检索,结合向量检索与全文检索,提高医疗文献的召回精度,以满足用户需求。
本文介绍了如何使用Java和Python在本地搭建AI问答系统,涵盖了大语言模型的概念、架构、训练和应用,以及Embedding技术和向量数据库的使用。还讲解了通过RAG技术提升模型准确性,并提供了使用LangChain和LangChain4J框架的具体实现步骤。
完成下面两步后,将自动完成登录并继续当前操作。