

AWS Glue 3.0 到 5.0 版本升级实践:中国区大规模 ETL 平台的迁移方法论
亚马逊AWS官方博客
·
Databricks ETL迁移决策框架
Databricks
·

构建SQL ETL管道:数据工程师的完整指南
Databricks
·
Databricks在2026年SIGMOD大会上
Databricks
·
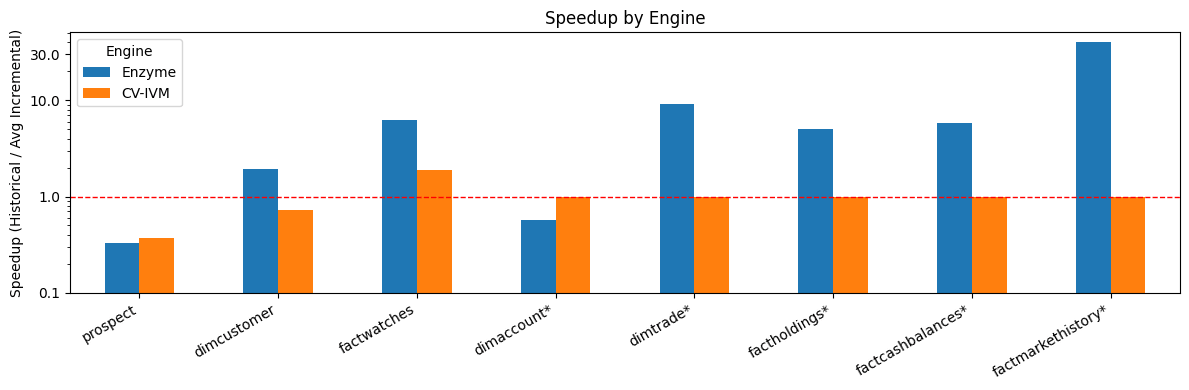
宣布Lakebase变更数据馈送(CDF)
Databricks
·
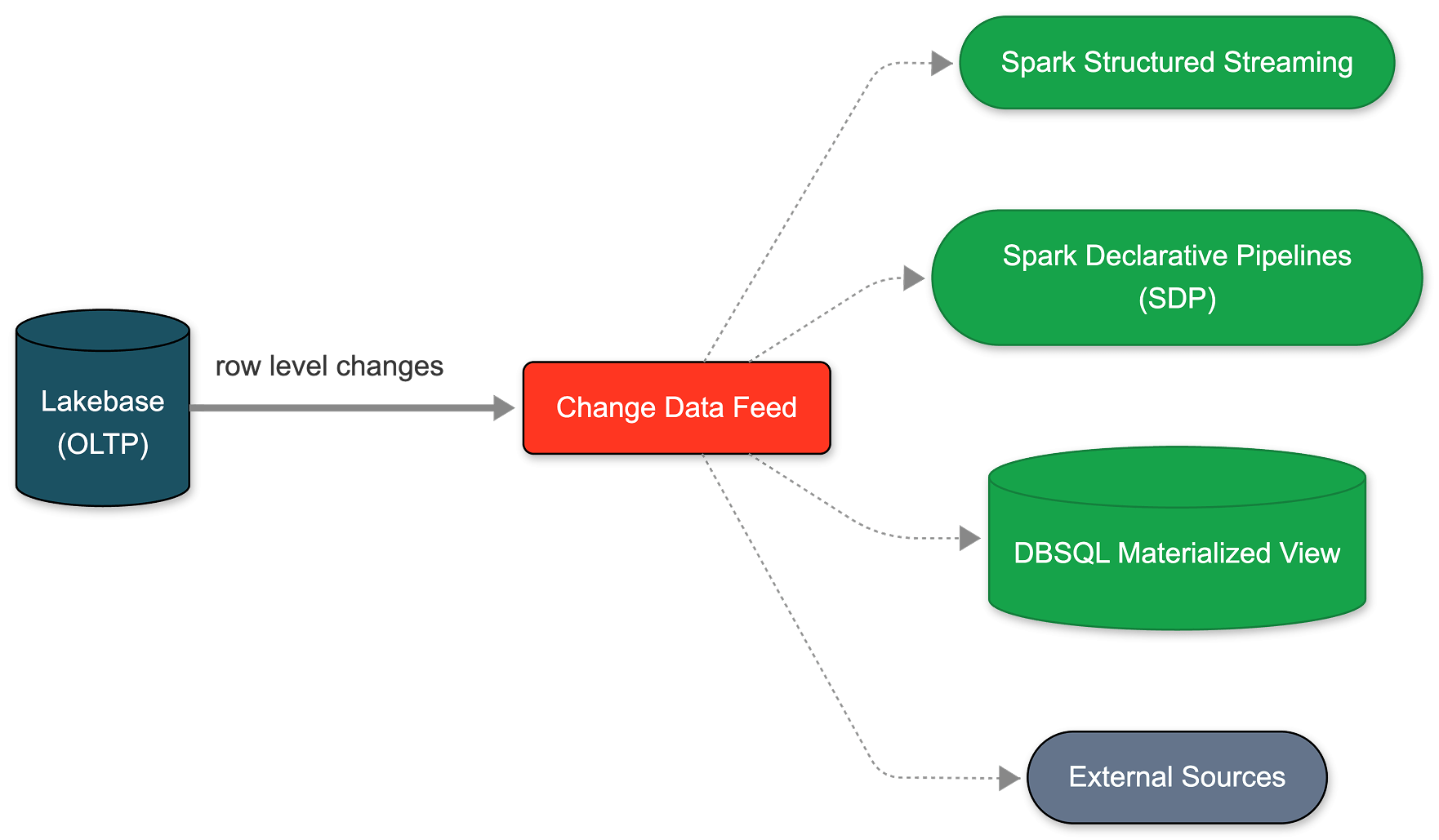
宣布Databricks分析工程师学习路径
Databricks
·

发现一个很有意思的 .NET 8 开源项目:AI 工作流引擎 Slickflow
dotNET跨平台
·

实时更新还是ETL?如何选择合适的工具
Blog - Supabase
·
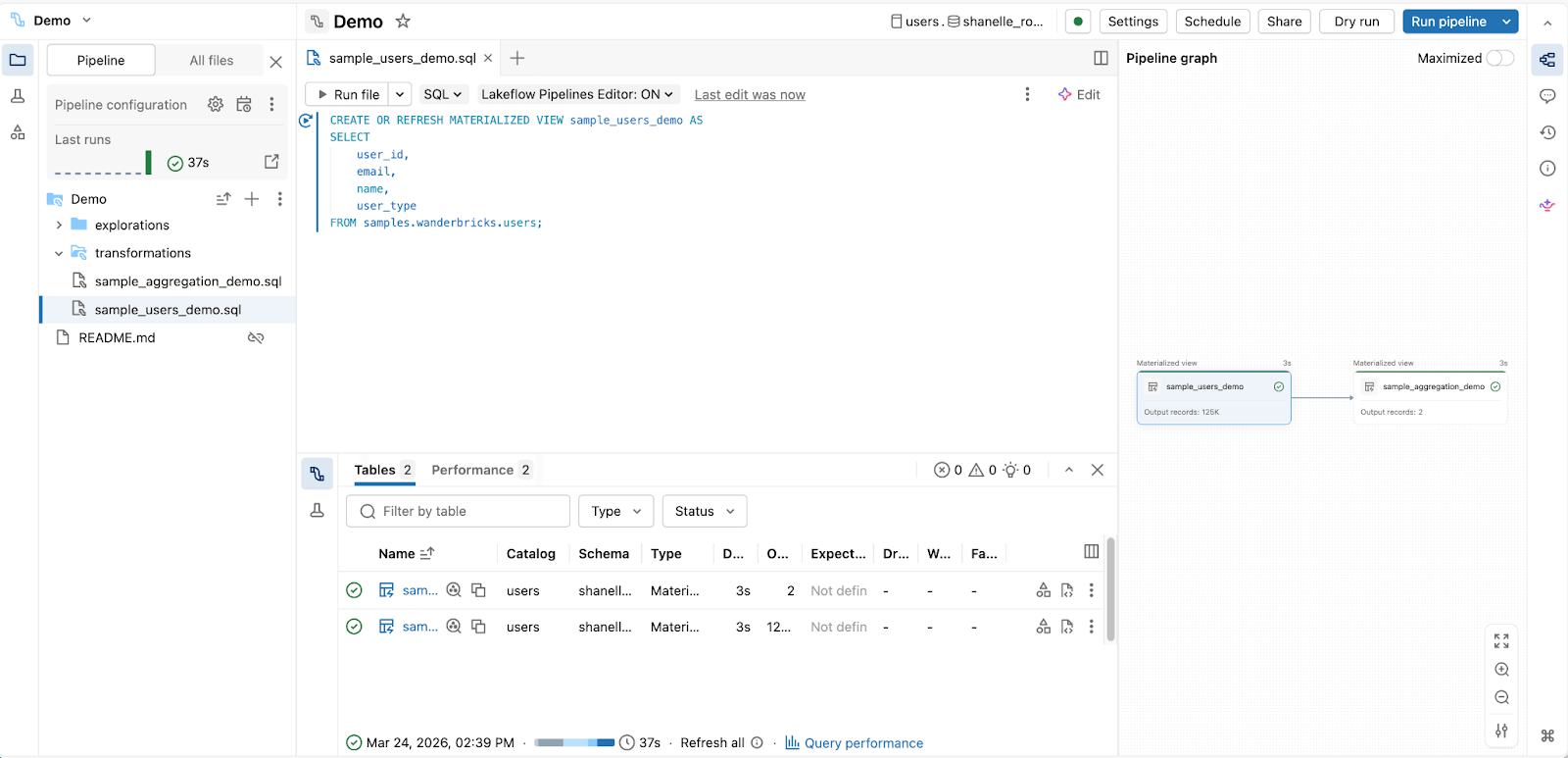
重新思考现代数据平台的SQL ETL
Databricks
·

数据工程师和数据科学家的AI数据转换指南
Databricks
·
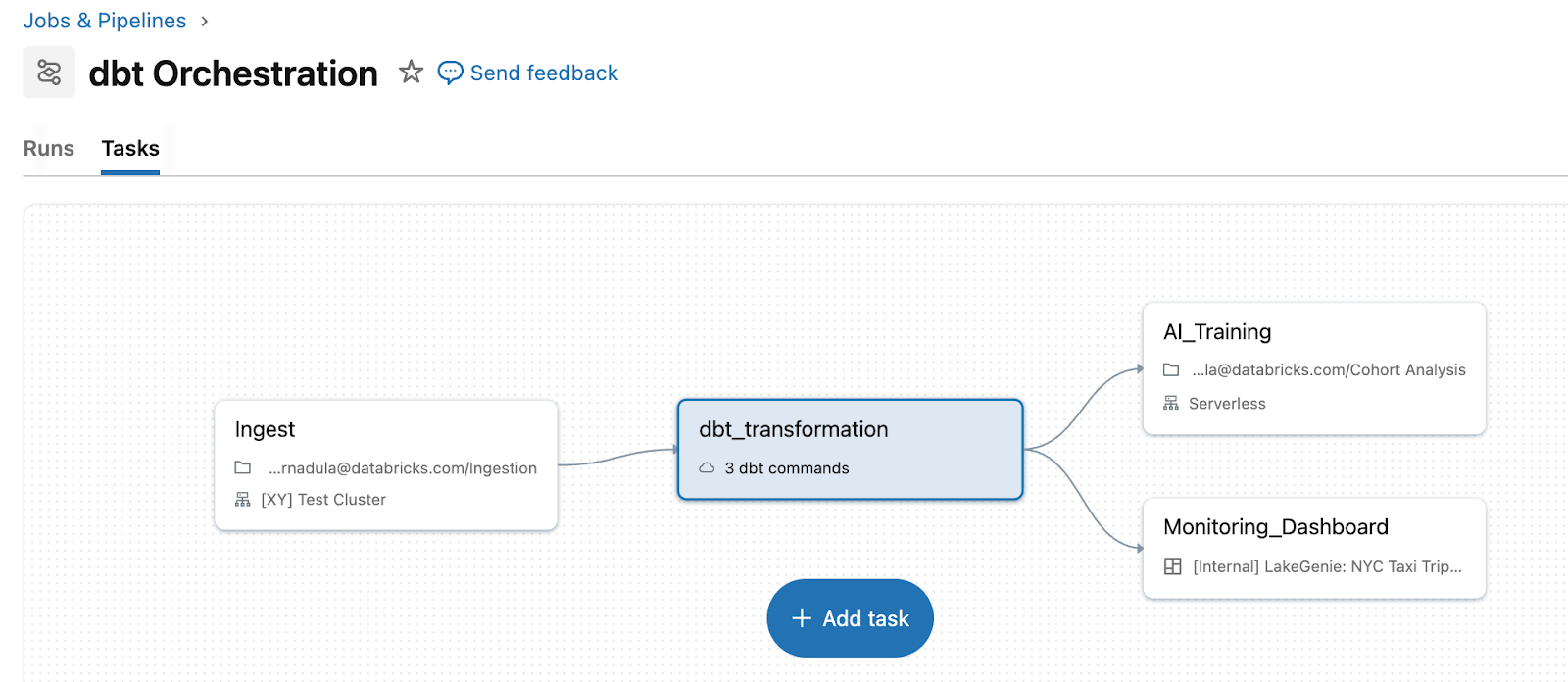
开放平台,统一管道:为何在Databricks上使用dbt能够加速数据转型
Databricks
·

Vibhor Kumar:pg_background v1.9:一种更平静、更实用的后台SQL执行方式
Planet PostgreSQL
·

主机数据迁移中选择ETL的五个错误理由
BMC Software | Blogs
·

什么是数据工程?
Databricks
·

数据工程师的七大Python ETL工具
KDnuggets
·

从ETL到自主性:2026年的数据工程
The New Stack
·

Mooncake为Databricks带来了丰富的事务处理能力
The New Stack
·

介绍 Supabase ETL
Blog - Supabase
·
