视觉语言模型(VLMs)结合视觉与文本理解,适用于无障碍助手和机器人等应用。Apple的FastVLM通过高分辨率图像的混合架构显著提升了准确性和效率,解决了二者之间的权衡,适合实时应用。
机器之心数据服务现已上线,提供高效稳定的数据获取,简化数据爬取流程。
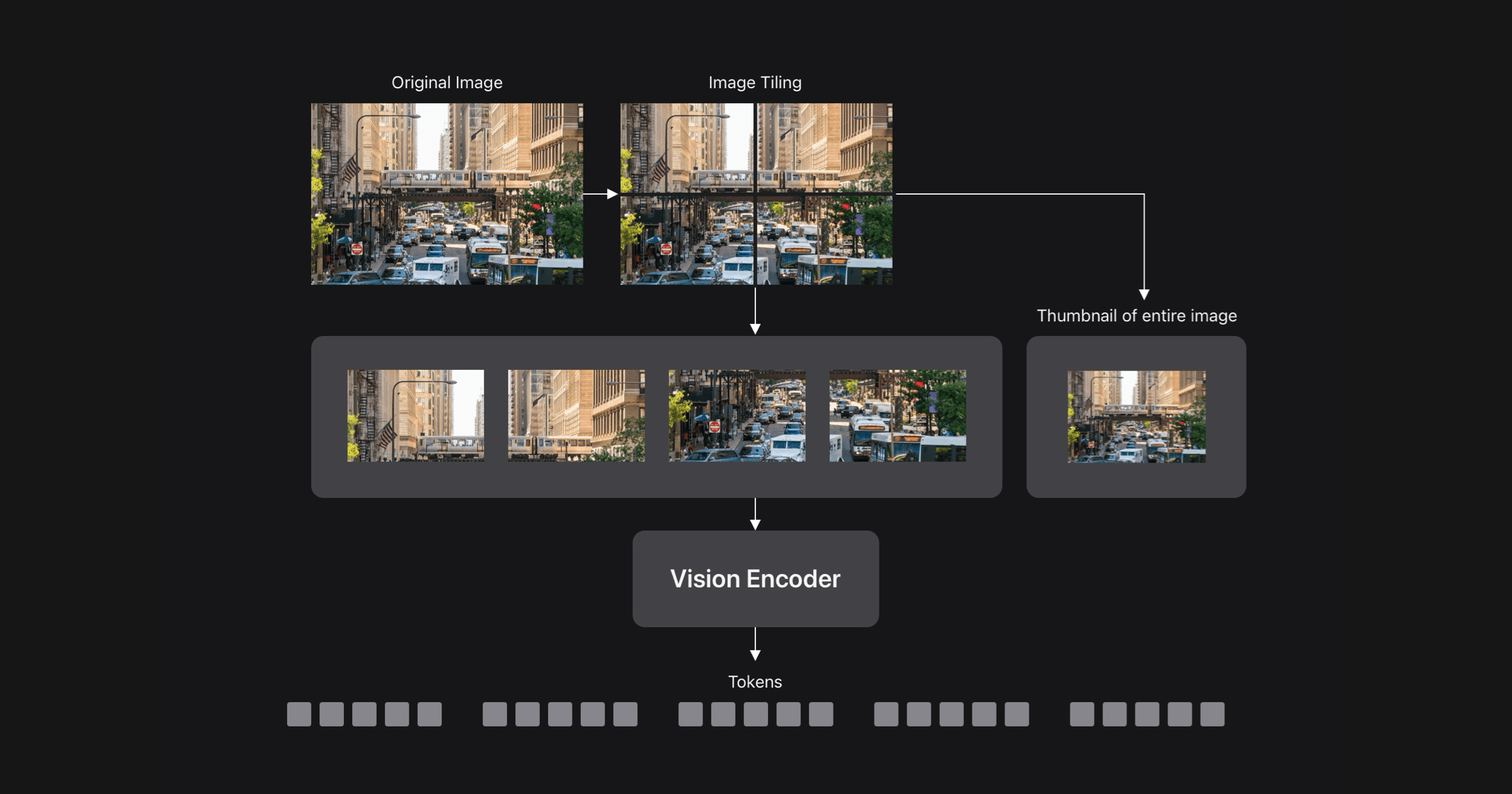
提升图像分辨率对视觉语言模型(VLM)性能至关重要,但高分辨率下的视觉编码器效率低。FastVLM模型通过优化图像分辨率、延迟和准确性之间的平衡,采用新型混合视觉编码器FastViTHD,显著减少编码时间和视觉标记数量。与之前的方法相比,FastVLM在保持性能的同时,首次标记时间提升了3.2倍,并在高分辨率下表现优异。
完成下面两步后,将自动完成登录并继续当前操作。