OpenStack最新版本Flamingo发布,显著减少技术债务,增强企业功能,提升并发性、安全性和硬件支持。该版本由480名贡献者开发,支持全球5500万计算核心,采用现代Python异步框架,改善性能和可扩展性,并实施六个月的升级发布周期。
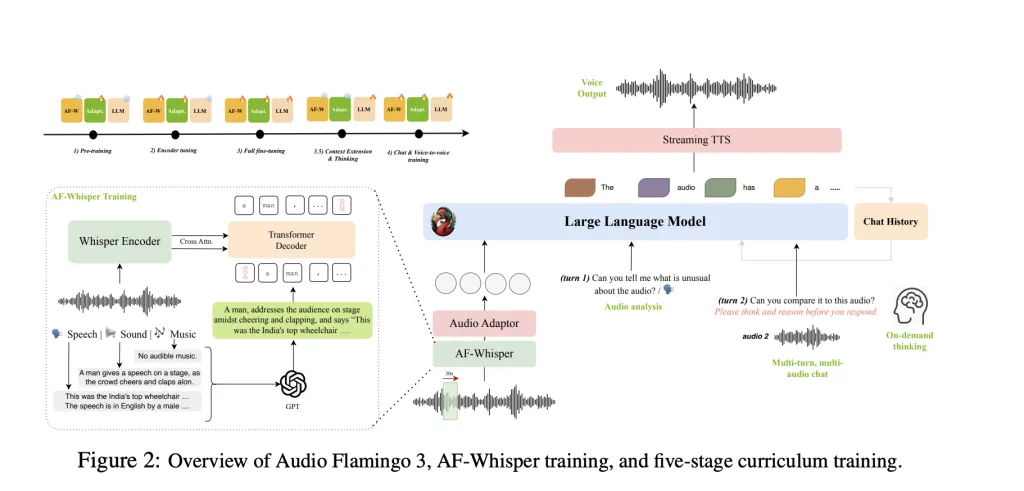
NVIDIA推出的Audio Flamingo 3(AF3)是一个开源的大型音频语言模型,具备理解和推理音频的能力,支持最长10分钟的音频输入,能够进行多轮对话和思维链推理,显著提升音频处理的准确性和效率,表现优异,推动通用音频智能的发展。
作者正在开发一种名为“flamingo”的编程语言,已实现简单的Pratt解析器和解释器,支持函数、变量、结构体、条件语句和循环等功能。解释器使用Python编写,虚拟机则用Rust开发,计划将语言编译为中间表示(IR)。作者对进展感到满意,并将持续更新项目。
Audio-Visual Speech Recognition (AVSR) uses Whisper-Flamingo, a model that integrates visual features, to improve speech recognition and translation performance in noisy conditions for multiple languages.
IDEFICS是基于Flamingo的开放访问视觉语言模型,接受图像和文本输入并生成文本输出。有两个变体,参数分别为90亿和800亿。模型在公开可用的数据集和名为OBELICS的新数据集上进行了训练。模型的架构、训练方法和评估详见模型卡和研究论文。模型进行了偏见评估,并为项目制定了道德宪章。模型可在Hugging Face Hub上获取。
完成下面两步后,将自动完成登录并继续当前操作。