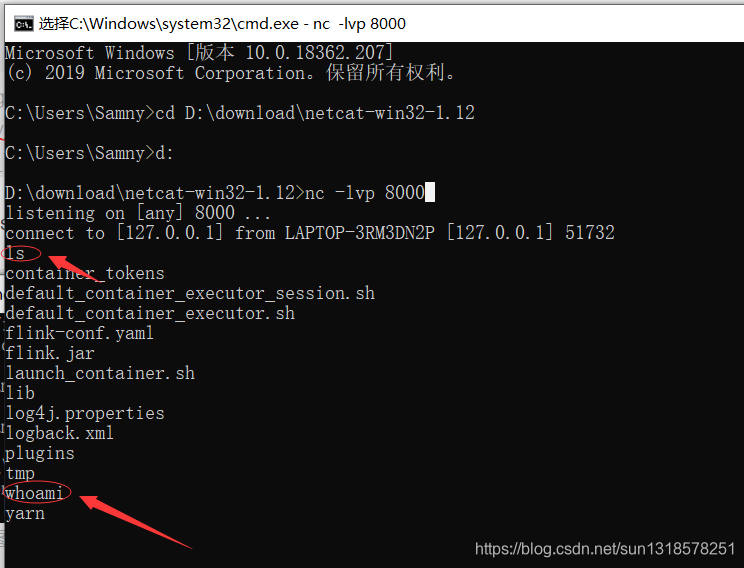
Apache Flink 存在高危漏洞,允许任意 Jar 包上传并导致远程代码执行,影响版本为 1.9.1 及以下。复现过程包括生成 payload、监听端口和上传 payload,建议使用 Sunny-ngrok 进行端口转发。提供了批量检测脚本的 GitHub 地址供研究学习使用。
本文讨论流式数据处理的规划,重点在于Kafka与Flink的结合。内容涵盖流处理基础、Kafka内核、Flink运行时、状态管理及交付语义,旨在解决实时数据链路中的关键问题,如事件时间、窗口处理、状态管理及故障模式。目标读者为数据平台工程师,帮助他们理解流式计算与批处理的差异,以及如何有效运维Kafka和Flink管道。
本文讨论了使用Kafka 3.x(KRaft)和Flink 1.20+进行流处理实验的复现步骤,包括环境设置、事件时间与处理时间窗口、Kafka日志解读、事务处理和检查点间隔等内容。实验结果将记录在output/目录中,以确保实验的准确性。
本文讨论了Flink中EmbeddedRocksDBStateBackend的机制,重点在于KeyGroup前缀、增量checkpoint的实现及其与RocksDB的关系。增量checkpoint依赖于不可变SST文件和MANIFEST,以确保数据一致性。文章还比较了Flink、TiKV和Kafka Streams在状态管理和容错机制上的差异,强调了设计与参数调优的重要性。
本文讨论了RocksDB中的列族(Column Family, CF)机制,强调其共享WAL和独立MemTable/SST的特性。CF允许在同一数据库实例中实现多组比较器和独立的压缩策略,以满足不同状态变量的隔离需求。文章还介绍了Flink如何将多种状态变量映射到不同的CF,以优化性能和管理。WAL的回收机制与CF的flush操作密切相关,影响整体性能。
本文探讨了RocksDB的内核机制,包括LevelDB、WAL、Compaction和Column Family等,重点分析了其在流计算和数据平台中的应用,尤其是在Flink和TiKV中的嵌入方式。同时讨论了写优化LSM的实现、读写路径、Compaction策略及其对性能的影响,适合流计算工程师和存储开发者阅读。
本文介绍了 Apache Flink 的运行时架构,重点讲解了 JobManager、TaskManager 和 Slot 的角色及功能。Flink 的数据流作业通过 StreamGraph、JobGraph 到 ExecutionGraph,最终在 TaskManager 的 Slot 上执行。文章还探讨了算子链的合并条件、并行度与资源管理的关系,以及如何通过 SlotSharingGroup 实现资源隔离与利用率优化。这些概念有助于优化 Flink 作业的性能与资源配置。
本文探讨流式数据处理中的关键问题,包括事件时间、窗口、Kafka与Flink的状态管理、checkpoint机制及其在乱序事件中的应用,重点分析如何实现端到端的exactly-once语义,以及背压和数据倾斜等故障的诊断与处理。
本文探讨流式数据处理的核心概念,包括流处理、批处理和微批的区别,以及如何通过Kafka和Flink实现有状态计算。强调流处理在无界输入和乱序情况下的容错机制,比较流表对偶与Lambda/Kappa架构,指出流处理的关键在于定义输出时机、状态存储和容错策略。
本文讨论了Flink中的时间语义及其在有状态计算中的应用,主要包括事件时间、处理时间和摄取时间的定义与选择。重点介绍了watermark的生成与处理策略,以及如何通过允许的迟到时间和侧输出处理迟到数据。最后,强调了事件时间在流式聚合与批处理对齐中的重要性。
本文讨论了Flink中的三种窗口类型:滚动窗口、滑动窗口和会话窗口。详细分析了每种窗口的定义、状态管理、输出频率及适用场景。滚动窗口固定不重叠,滑动窗口允许重叠,会话窗口根据事件间隔动态调整。此外,还介绍了触发器和状态裁剪器的功能,以及如何选择合适的窗口类型以优化流处理任务的性能。
本文讨论了Apache Kafka 3.x中的幂等生产者和事务生产者的工作机制。幂等生产者通过Producer ID和序列号消除重复消息,而事务生产者确保多分区消息的原子性。消费者隔离级别分为read_committed和read_uncommitted,影响事务数据的可见性。Flink与Kafka结合实现了端到端的exactly-once语义,确保数据一致性。
本文讨论了Flink DataStream API的工作原理,包括作业结构、数据流转换、shuffle策略及其对性能的影响。重点介绍了keyBy操作、ProcessFunction的使用及定时器注册,强调了状态管理在流处理中的重要性,并通过示例展示了事件时间和窗口聚合的处理,简要说明了Flink 2.x版本。
本文讨论了Flink中的Keyed State及其管理,介绍了五种状态类型(ValueState、ListState、MapState、ReducingState、AggregatingState)的适用场景和特点。同时分析了HashMapStateBackend与EmbeddedRocksDBStateBackend的优缺点,以及状态的TTL配置和清理策略。最后,提供了状态大小估算的方法,指出滑动窗口和无限MapState可能导致的状态膨胀问题。
本文讨论了Flink中的Checkpoint机制,强调其在有状态流作业中的重要性。Checkpoint通过绑定数据源读取位置和算子状态,确保作业失败时能够恢复一致性状态。文章介绍了Chandy-Lamport快照算法的变体、对齐与非对齐Checkpoint的优缺点,以及CheckpointCoordinator的生命周期和Kafka源的offset管理,并提供了调优建议以优化Checkpoint的性能和可靠性。
本文讨论了Flink中Savepoint与Checkpoint的区别及应用场景。Savepoint是用户手动触发的可移植快照,适用于版本升级和拓扑变更;Checkpoint是自动生成的,主要用于故障恢复。Savepoint支持状态迁移和并行度调整,但需注意UID管理和状态兼容性。文章还提供了操作命令、常见异常处理及版本升级检查清单,强调了在生产环境中使用Savepoint的重要性。
本文讨论了Flink中RocksDB状态后端的工作机制,包括状态存储、增量检查点和读写路径。RocksDB通过将状态序列化为字节数组存储在本地磁盘,支持增量检查点,从而优化状态管理。文章分析了RocksDB的Column Family与KeyGroup的映射,以及如何通过增量检查点减少I/O开销,并提供了可复现实验步骤以验证相关机制。
本文探讨了Flink中RocksDB的状态管理与优化,分析了状态膨胀的原因及其对磁盘占用的影响,主要涉及窗口状态、TTL和MapState的无限增长等问题。提出通过调整RocksDB参数和设计来优化性能,强调在hot key倾斜情况下,改进状态设计比单纯调参更有效,并提供了调优建议和监控指标。
本文探讨了流式数据处理中的交付语义,重点分析了Flink的checkpoint机制与Kafka的offset管理。建立了三层模型:Source、引擎和Sink,讨论了at-most-once、at-least-once和exactly-once的定义及修复手段。强调端到端语义由最弱环决定,指出即使使用exactly-once,Sink仍需支持2PC或幂等操作,以避免重复写入。
完成下面两步后,将自动完成登录并继续当前操作。