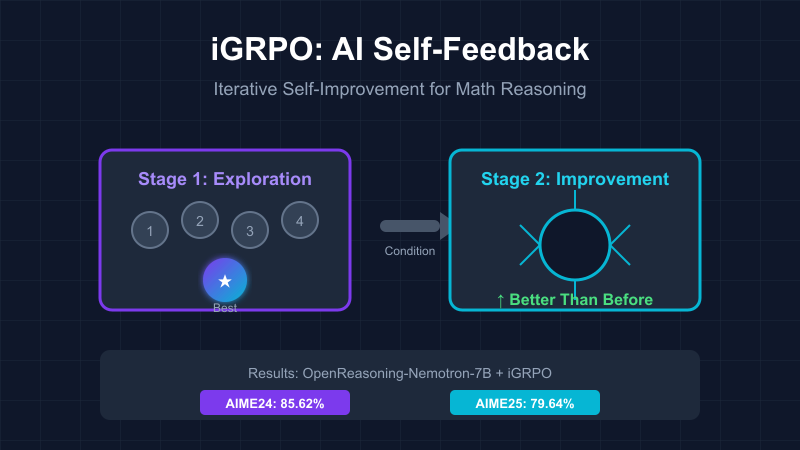
本文提出了iGRPO(迭代组相对策略优化),通过自我反馈提升AI的数学推理能力。该方法包括探索与选择、条件化改进两个阶段,显著提升多个基准测试的表现,且无需复杂的外部反馈。iGRPO的理念与人类学习相似,强调超越自我,具有广泛应用潜力。
完成下面两步后,将自动完成登录并继续当前操作。