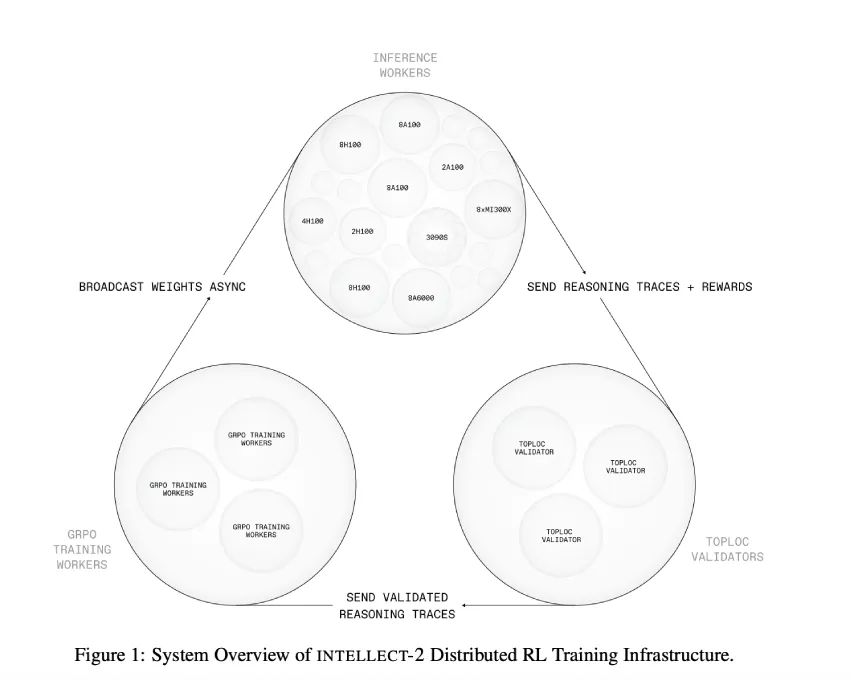
Prime Intellect发布了基于去中心化网络的32亿参数语言模型INTELLECT-2,采用完全异步强化学习。该模型使用PRIME-RL框架,分离生成、更新和广播任务,通过SHARDCAST分发模型权重,并通过TOPLOC验证推理结果。INTELLECT-2在285,000个数学和编程任务上训练,表现优于前代模型。未来计划包括提升推理与训练的计算比率及整合更多工具。
全球首个分布式强化学习模型INTELLECT-2发布,利用闲置算力进行训练,显著降低成本,性能接近DeepSeek-R1。该模型去中心化,任何人可参与训练,可能改变大公司对算力的垄断。团队已获得Karpathy等投资,未来将扩展去中心化训练。
INTELLECT-2 是首个通过分布式算力训练的 320 亿参数大模型,采用 PRIME-RL 框架以确保训练的稳定性和效率,已开源模型、代码和数据。用户可通过提供算力获得收益,H100 每小时 20 元,RTX4090 每小时 2.3 元。
INTELLECT-2是PrimeIntellect推出的32B参数推理模型,采用去中心化异步强化学习框架,克服了集中式训练的局限性。该模型在多个基准测试中超越QwQ-32B,展现出更强的推理能力和灵活性,支持可重复性和扩展性。
完成下面两步后,将自动完成登录并继续当前操作。