今晚19点,KTransformers项目将直播,介绍如何在本地使用2GPU+2CPU微调超大模型。清华大学的章明星教授和李沛霖将分享低成本LoRA微调技术及项目进展,欢迎预约观看。
KTransformers、LLaMA-Factory和SGLang提供低成本、低内存的本地微调和推理方案。通过LoRA微调和GPU+CPU异构执行,用户可以在资源有限的情况下有效训练和推理超大规模MoE模型。这种集成使得在普通硬件上处理大模型成为可能,显著降低了GPU内存需求并提高了吞吐量。
KTransformers是趋境科技与清华大学联合研发的高性能异构推理框架,专注于大模型推理。该框架通过CPU与GPU协同优化算力利用,提升推理效率,支持低算力环境下的大模型应用。其论文入选国际顶会SOSP 2025,获得全球认可,并与主流框架SGLang合作,推动开发者创新。
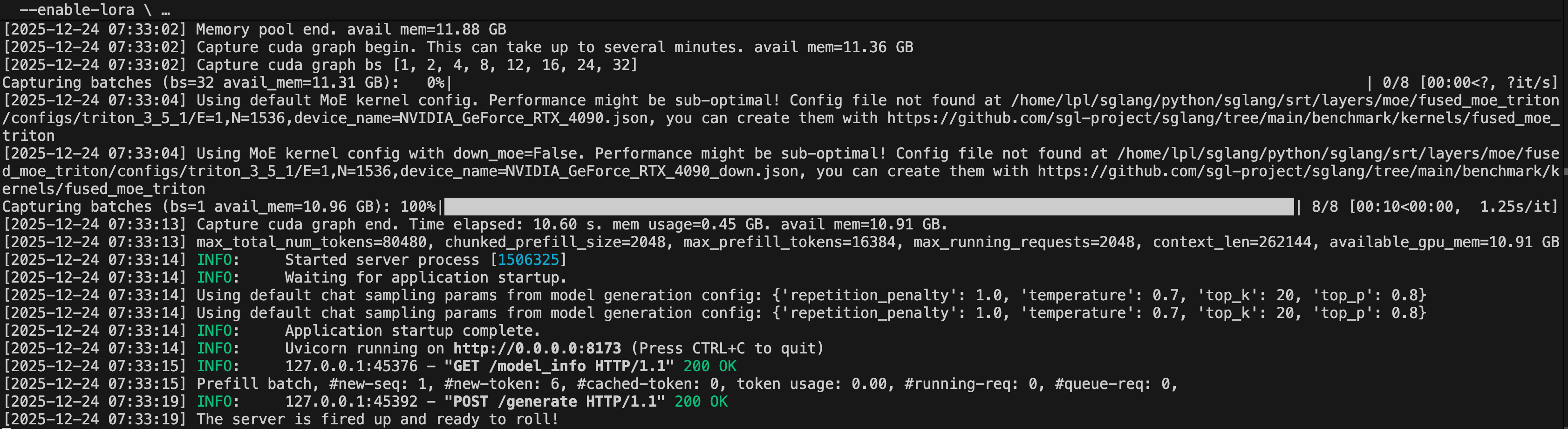
KTransformers是一个新型Transformers框架,通过内核优化和并行策略显著提升LLM推理速度,尤其在MOE模型上表现优异。其用户友好的接口支持在资源受限的环境中部署,官方测试显示在14GB显存下可实现高达8.73 tokens/s的推理速度,速度提升可达27.79倍。
文章内容缺失,无法提供有效摘要。请提供完整的文章文本以便进行总结。
完成下面两步后,将自动完成登录并继续当前操作。