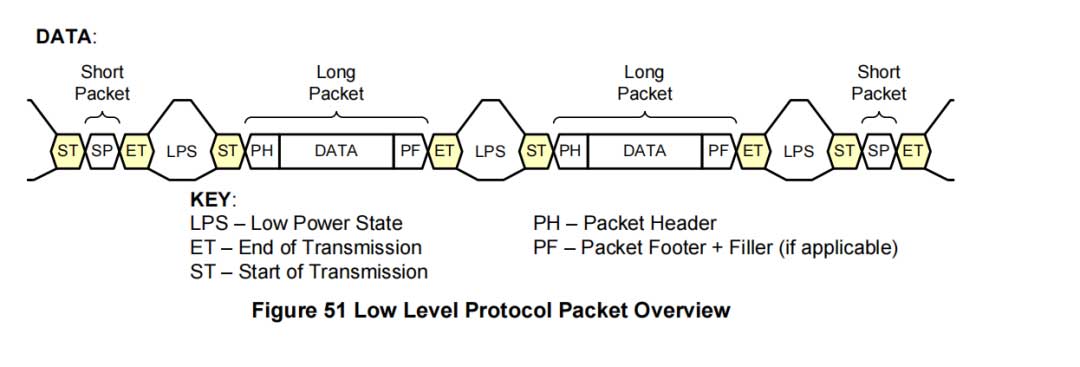
本文介绍了mipi_CSI-2_specification_v2-1-2018版本中的低级协议(LLP)的内容,包括LLP的特点、数据包格式和结构,以及数据标识符和虚拟通道标识符的作用。
本文介绍了一种使用深度神经网络和新正则化层 Batch Averager 的方法,将有标注数据的深度神经网络转换为无标注学习的方法。作者通过 Twitter 用户的 tweets 和个人资料图片,预测 Twitter 用户的性别和种族 / 民族信息,并发现深度 LLP 方法在文本和图片分类方面均优于基线方法,并且协同训练算法可以将文本和图片分类的绝对 F1 值分别提高 4%和 8%。最后,采用文本和图片分类器的集合进一步平均提高了绝对 F1 值 4%。
完成下面两步后,将自动完成登录并继续当前操作。