本文讨论了MinHash和SimHash两种算法在大规模相似度检测中的应用。MinHash适用于Jaccard相似度,常用于文本去重和抄袭检测;SimHash适用于Cosine相似度,适合推荐系统。文章详细推导了算法原理、实现方法及其在搜索引擎和推荐系统中的应用经验,强调了在处理亿级文档时的效率与精度权衡。
本研究提出了一种基于MinHash和HyperLogLog(HLL)数据草图的实时设备覆盖预测系统,显著提高了预测速度和准确性,误差率控制在5%以内,有效减少客户入驻时间,降低潜在损失。
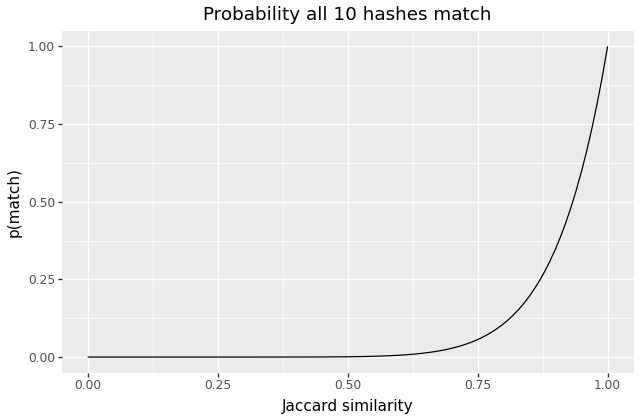
本文探讨了使用Jaccard相似度和MinHash技术进行近似去重的方法。通过设定相似度阈值,可以识别相似文档。Jaccard相似度通过比较集合的交集与并集来衡量相似性,而MinHash则通过生成文档的“签名”来高效估算相似度。这种方法适用于大规模文档集合,有效识别近似重复内容。
完成下面两步后,将自动完成登录并继续当前操作。