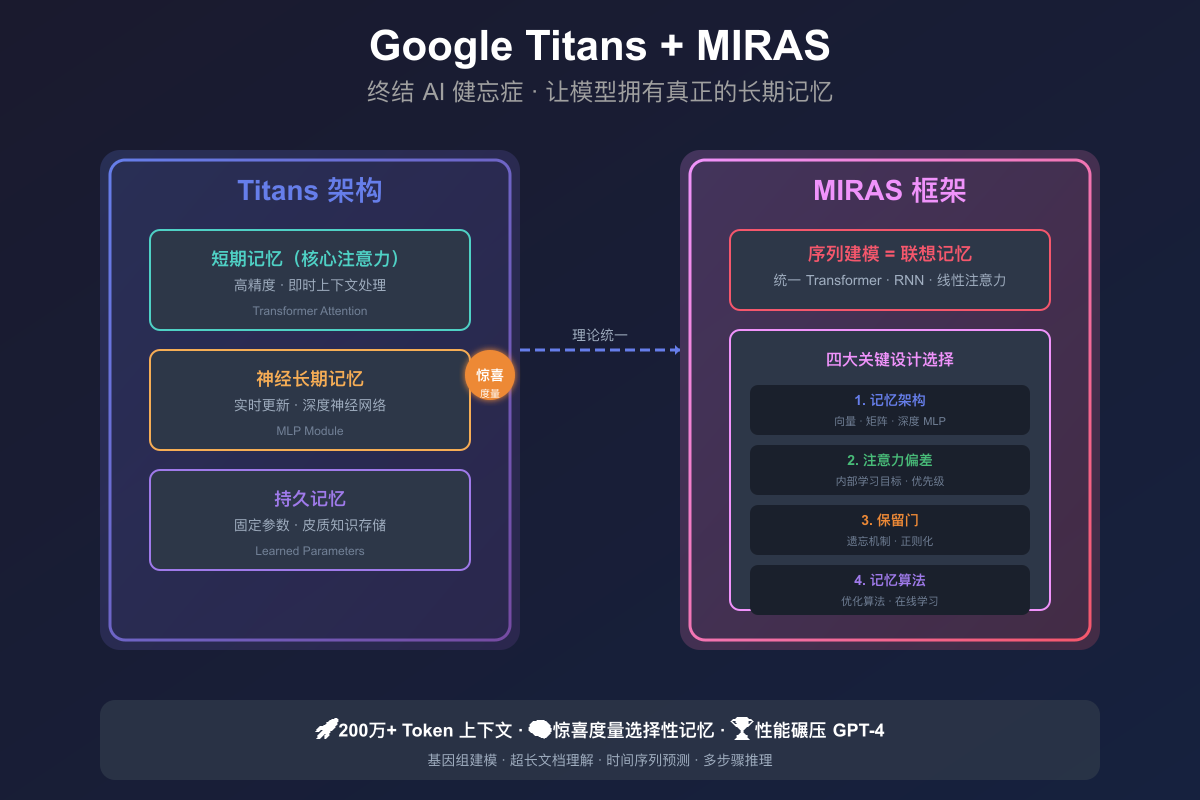
2017年,Transformer架构引入了注意力机制,但计算成本随着序列长度增加而显著上升。Google Research推出Titans和MIRAS架构,结合RNN的速度与Transformer的准确性,支持超长上下文处理。Titans模仿人脑记忆,采用短期、长期和持久记忆,通过“惊喜度量”选择性更新信息。MIRAS统一序列建模方法,拓展了设计空间,推动AI记忆系统的发展。
谷歌在NeurIPS 2025上推出了新架构Titans和MIRAS,突破了Transformer在超长上下文处理中的限制。Titans结合了RNN的速度与Transformer的性能,能够动态更新记忆,扩展上下文至200万token。MIRAS则提供统一的序列建模框架,优化信息整合与记忆更新。这些新架构在处理长序列时优于现有模型,标志着AI领域的重要进展。
完成下面两步后,将自动完成登录并继续当前操作。