本研究提出了一种新型对抗攻击方法,针对神经机器翻译(NMT)模型。通过在句子间插入一个词,研究者能够使第二个句子在翻译中被忽略,从而隐藏恶意信息。实验结果显示,超过50%的NMT模型对这种攻击表现出脆弱性。
本研究提出了一种利用单语语料库和生成对抗网络(GAN)相结合的新方法,以增强低资源语言翻译任务的训练数据并提高翻译质量。该方法通过回译、数据增强和无监督神经机器翻译等技术,有效提高了翻译性能。
本文研究了大型语言模型在多语言机器翻译中的优势与挑战,评估了四种模型在102种语言上的表现。研究发现,低资源语言的翻译能力较弱,尤其是ChatGPT在84.1%的低资源语言中表现不如传统模型。提出的新微调方法ALMA显著提升了翻译性能,并探讨了通过上下文学习和生成式翻译范式改善翻译质量的途径。
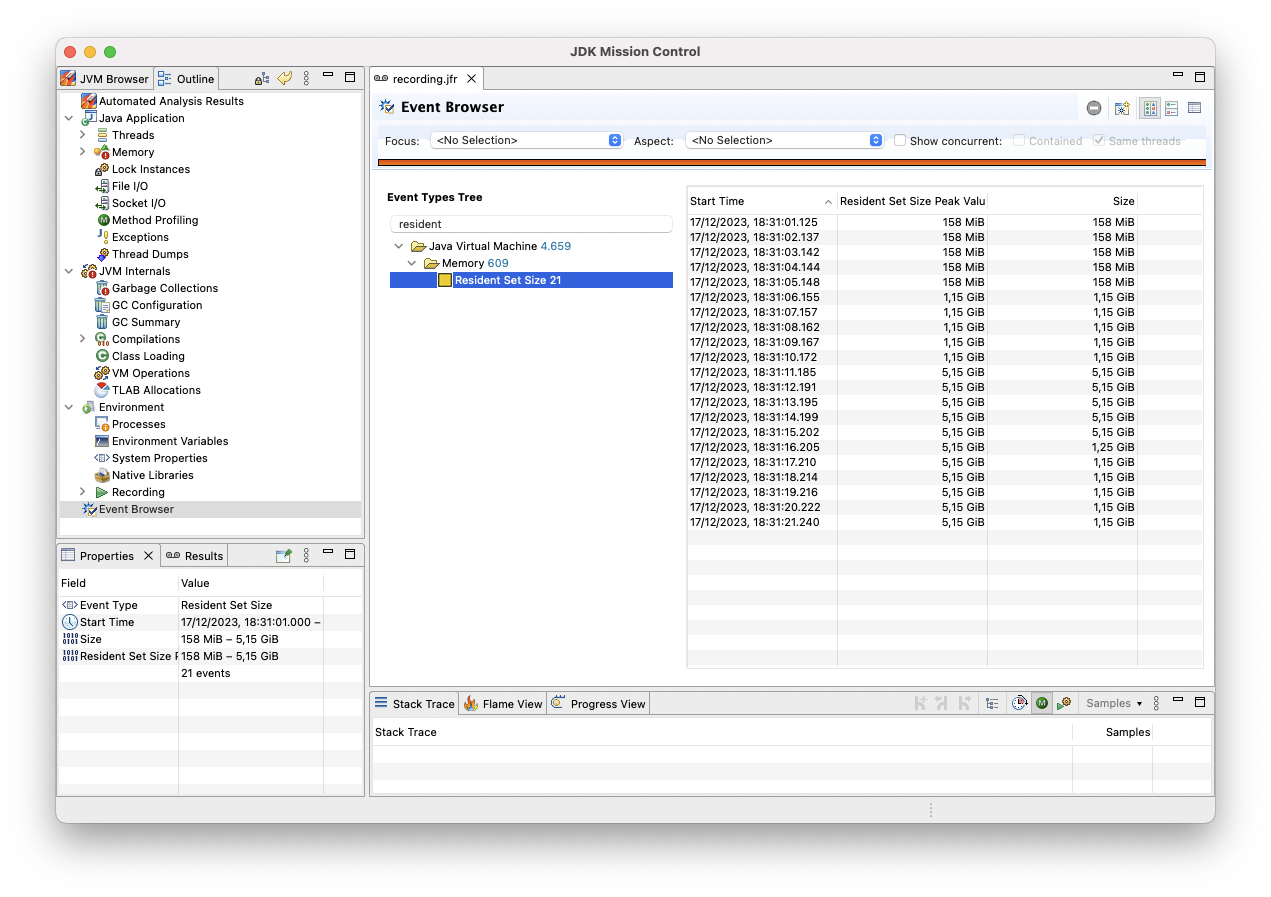
本文介绍了使用JFR报告NMT数据的方法,包括直接字节缓冲区和Foreign Memory API分配堆外内存。还讨论了JFR中控制NMT的设置和在JDK Mission Control中查看NMT数据的方法。最后,介绍了使用JFR记录Resident Set Size(RSS)事件来跟踪内存消耗。
本文探讨神经网络机器翻译在低资源条件下性能下降的原因,并提出适应低资源环境的注意事项和最佳实践。实验结果表明,经过优化的NMT系统可以在没有使用其他语言辅助数据的情况下,比以前报告的更少数据超越基于规则的机器翻译,BLEU指标超过4个点。
本文使用Tensor2Tensor框架和Transformer模型进行神经机器翻译实验,比较了关键参数对翻译质量、内存使用、训练稳定性和时间的影响,并给出了改进建议。
完成下面两步后,将自动完成登录并继续当前操作。