
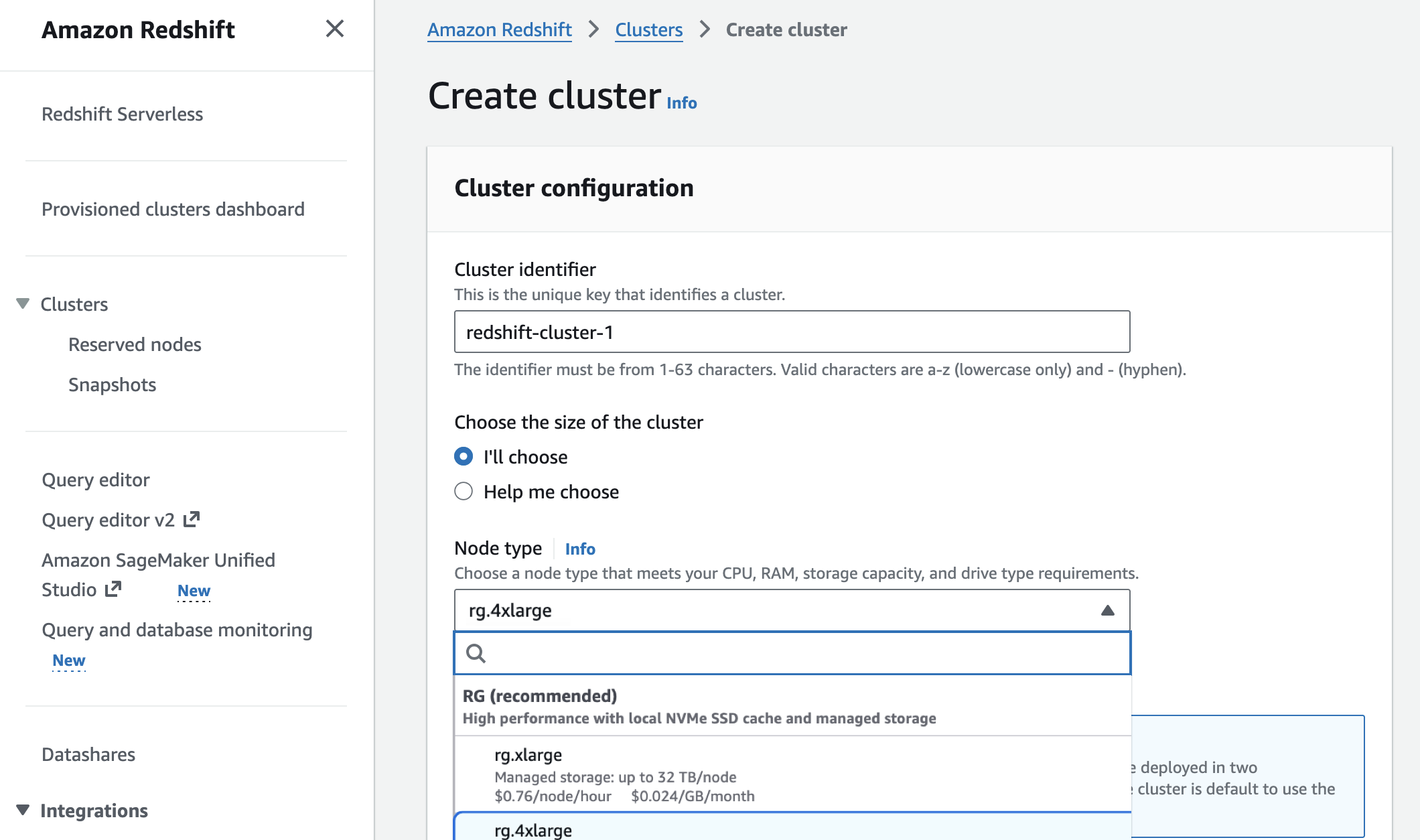
DataGrip 2025.3:从控制台迁移到查询文件,连接云服务提供商,Amazon Redshift的自省级别,以及更多!
The JetBrains Blog
·

Redshift 性能调优2 – 经典调整(Classic Resize)
亚马逊AWS官方博客
·
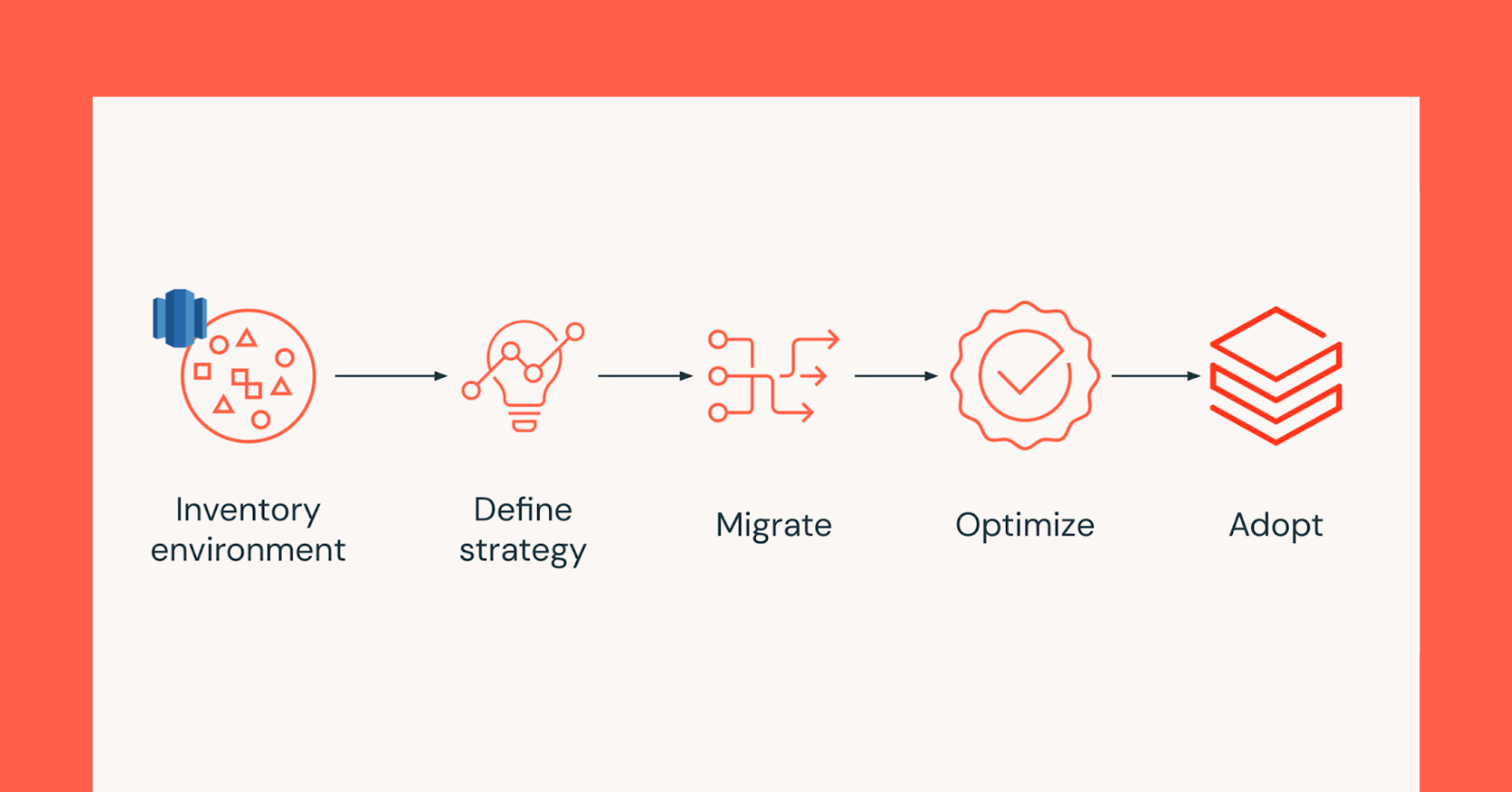
从Redshift迁移到Databricks:数据团队的实用指南
Databricks
·
Redshift性能调优 1 – 并发扩展(Concurrency-Scaling)
亚马逊AWS官方博客
·
基于 CoT 协调多 MCP Tool — 智能运维 Redshift
亚马逊AWS官方博客
·
基于 Amazon Q Developer+Remote MCP 访问 Amazon Redshift
亚马逊AWS官方博客
·
Strands Agents 快速上手 – dbt on Amazon Redshift 数据质量智能体
亚马逊AWS官方博客
·

如何修复Redshift存储过程中的语法错误
DEV Community
·

基于 Apache Kafka 和 AWS 构建端到端的无服务器流式 ETL 管道
亚马逊AWS官方博客
·

AWS Redshift:您的数据仓库强大助手
DEV Community
·

修复 Redshift 清理操作以优化查询性能
DEV Community
·
基于 Datahub +Redshift 自动生成字段级血缘
亚马逊AWS官方博客
·

Redshift Serverless:通过工作负载管理(WLM)实现成本优化
DEV Community
·
数据架构的云原生迭代:从 Snowflake 到 AWS Data Lake
亚马逊AWS官方博客
·
