Databricks宣布,Mosaic AI Model Training现在支持在微调Meta Llama 3.1模型系列时的完整上下文长度为131K个标记。这使得客户能够使用长上下文长度的企业数据构建更高质量的Retrieval Augmented Generation (RAG)或工具使用系统。Llama 3.1模型的长上下文长度能够对大量输入信息进行推理,减少在RAG中的分块和重新排序的需求,或为代理提供更多工具描述。Databricks通过使用序列并行性来优化微调过程,将序列的激活内存分布到多个GPU上,减少了GPU内存占用并提高了训练效率。微调过程中使用的内部Llama表示使得序列并行性成为可能,同时提高了训练吞吐量并需要更小的内存占用。客户可以通过UI或以Python编程的方式开始微调Llama 3.1模型。
Retrieval Augmented Generation (RAG)是一种将大型语言模型(LLM)与内部知识库的新数据相结合的生成式AI技术,以生成更可靠的回答。RAG通过从知识库中检索相关信息并使用它来生成回答。RAG系统由语义搜索层和生成层组成。语义搜索层通过将文档转化为嵌入向量来构建知识库。生成层包括一个LLM和一个提示,指示LLM生成什么样的回答。RAG通过提供最新信息和减少AI幻觉来提高LLM的性能。
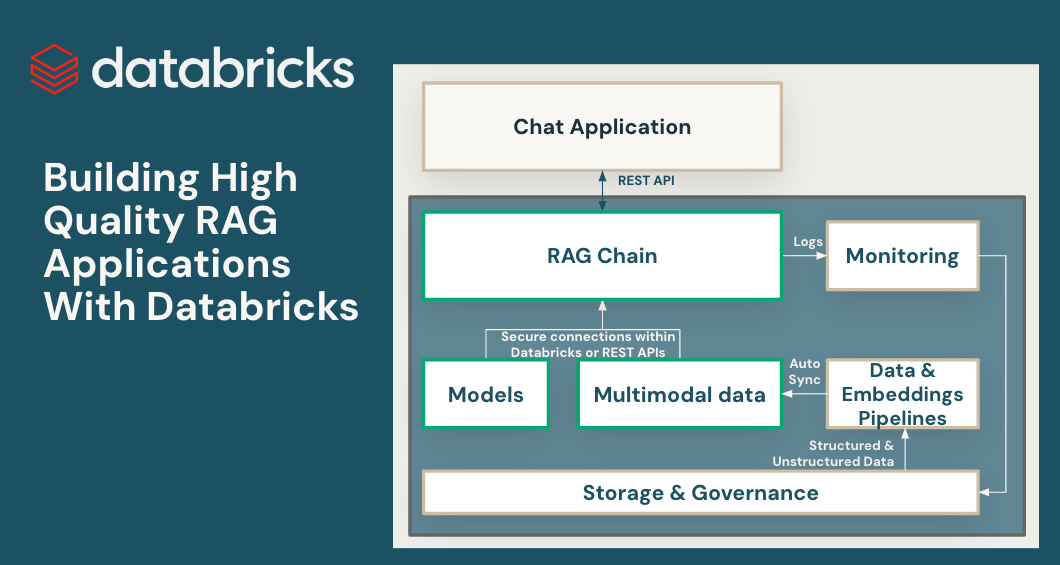
Databricks发布了Databricks Vector Search工具,可提高检索增强生成(RAG)和生成式人工智能应用的准确性。Vector Search允许在非结构化文档(如PDF和Office文档)上进行相似性搜索,并与Databricks Data Intelligence平台集成。它支持自动数据同步,并利用现有的安全和数据治理工具。Vector Search具有快速性能、低总拥有成本、内置治理和高检索质量。
Databricks推出了一套Retrieval-Augmented-Generation(RAG)工具,帮助用户使用企业数据构建高质量的生产级大型语言模型(LLM)应用。这些工具解决了实时数据服务、比较和调整基础模型以及确保生产中的质量和安全性等挑战。功能包括向量搜索服务、在线特征和功能服务、完全托管的基础模型以及灵活的质量监控界面。Databricks旨在提供统一的LLM开发和评估环境,允许用户访问领先的模型并根据关键指标进行比较。发布还包括Lakehouse Monitoring,用于监控RAG应用的质量。
完成下面两步后,将自动完成登录并继续当前操作。