

使用长序列微调Llama 3.1
Databricks
·

宣布 Databricks Vector Search 正式发布
Databricks
·
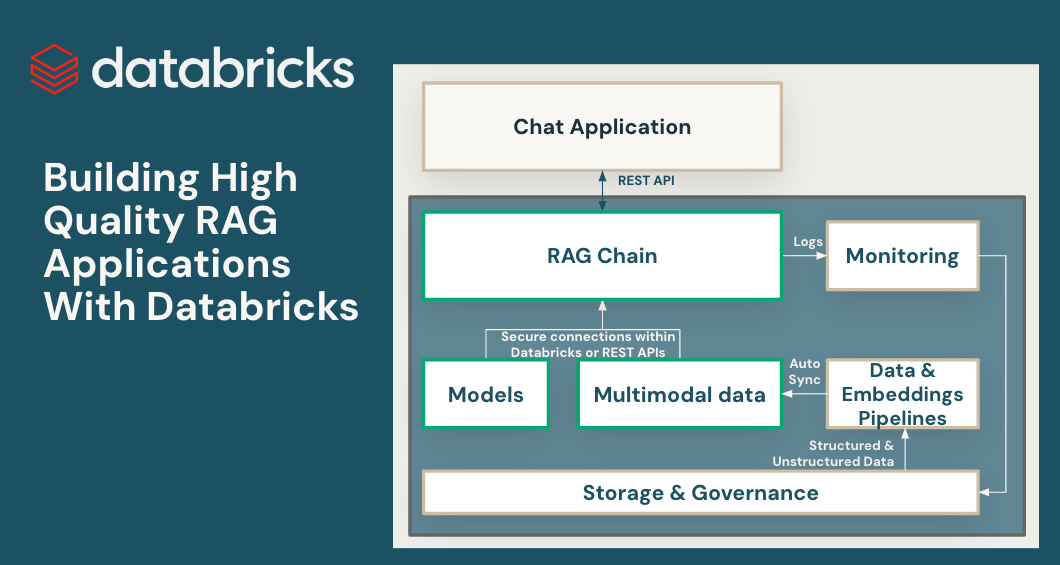
使用Databricks创建高质量的RAG应用程序
Databricks
·

预览版 – 使用 Amazon Bedrock 代理将根基模型连接到公司的数据源
亚马逊AWS官方博客
·
