

第740期:Pluggy、ABCs、Scrapy扩展及更多(2026-06-23)
PyCoder’s Weekly
·





什么是网页抓取?开发者的使用案例与应用
DEV Community
·

如何高效地使用Scrapy和代理IP进行数据爬取
DEV Community
·

通过extension实现scrapy定时调度
DEV Community
·

通过extesion实现scrapy-redis定时调度
DEV Community
·

2025年最佳网络爬虫工具
DEV Community
·

使用Beautiful Soup和Scrapy进行网页抓取:高效且负责任地提取数据
DEV Community
·

掌握网络爬虫:数据提取的技术与工具 🕷️💻
DEV Community
·

Scrapy Ja3改造
DEV Community
·

8个推荐的库
DEV Community
·

如何使用Scrapy和请求回调在Python中抓取产品页面(Etsy、亚马逊、eBay)
DEV Community
·

构建成功阿里巴巴爬虫的技巧
DEV Community
·
一日一技:在Scrapy中如何拼接URL Query参数?
谢乾坤|青南
·
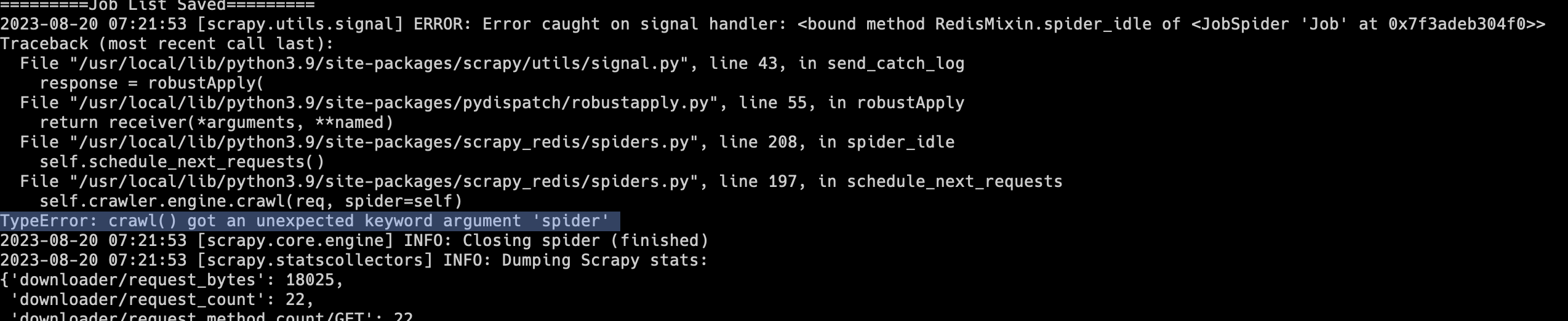
一日一技:Scrapy最新版不兼容scrapy_redis的问题
谢乾坤|青南
·
