后训练是一个复杂的数据流水线,包含多个阶段,如SFT、奖励模型和策略优化。每个阶段旨在将预训练模型转变为更符合人类指令和偏好的模型。SFT主要调整回答格式,奖励模型提供训练信号,策略优化提升生成候选的能力。评测确保模型的安全性和准确性,整体流程强调数据回流和持续优化,以提升模型性能和可靠性。
这篇文章讨论了监督微调(SFT)在语言模型训练中的重要性,强调数据质量、模板设计和损失函数的影响。SFT通过指令与回答对训练模型,确保模型能够有效生成助手回答。此外,SFT是后续强化学习(RLHF)的基础,强调样本去重、数据来源和模板一致性的重要性,以避免模型学习错误的行为模式。
PRISM团队的研究表明,监督微调(SFT)并未促进强化学习(RL),反而可能导致模型性能下降。研究提出了SFT、分布对齐和RL的三阶段流程,强调在多模态模型中,SFT引入的分布偏差需要单独处理。通过对抗博弈对齐分布,PRISM显著提升了模型在推理任务上的表现,修复了SFT的副作用。
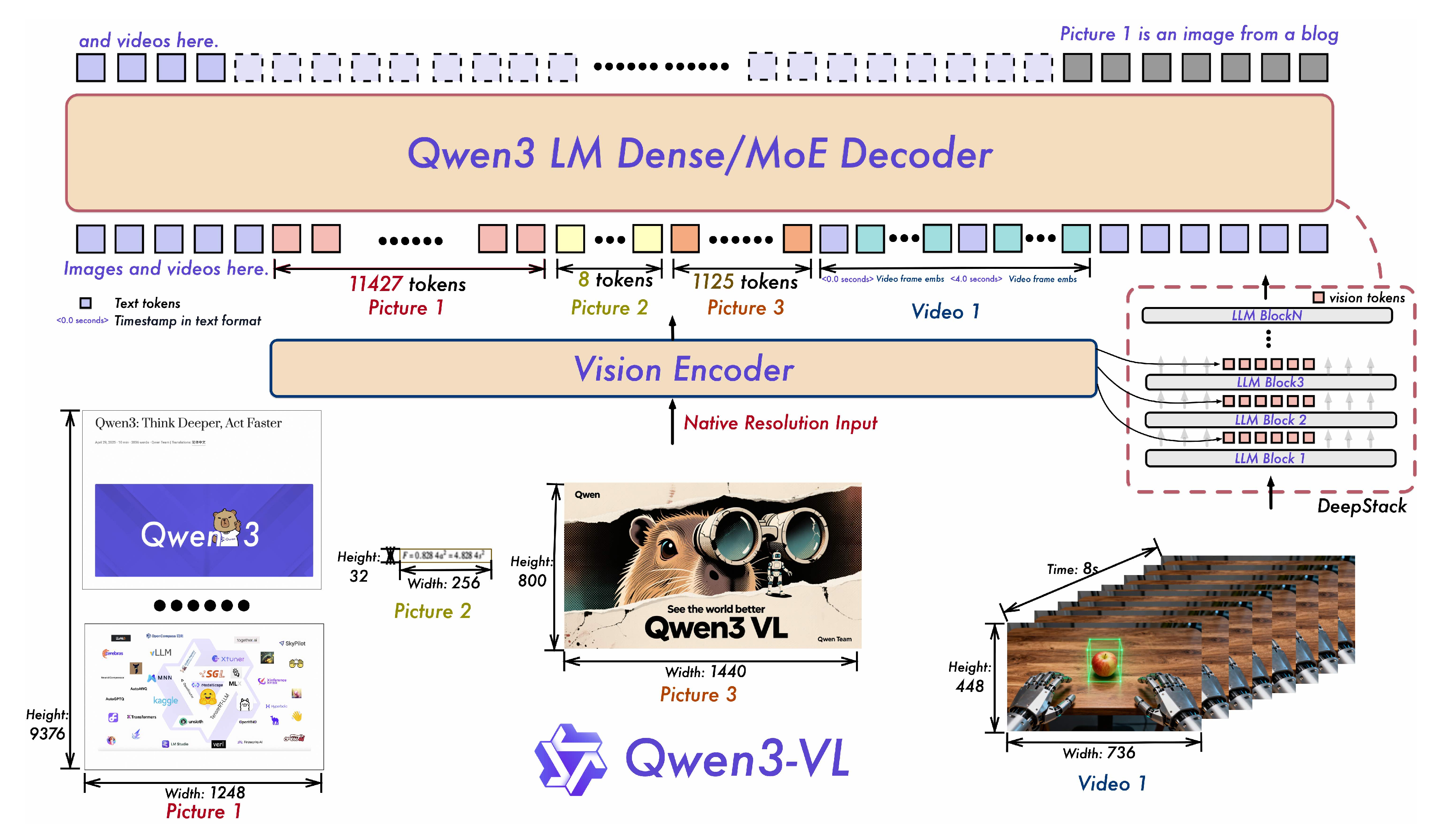
Qwen系列模型最新升级为Qwen3-VL,在视觉理解和视频处理方面有显著提升。引入多维旋转位置编码(MRoPE)和DeepStack技术,增强了对复杂场景的推理能力,支持长文档和长视频处理,具备更高的上下文长度和精确的时间定位能力,推动多模态理解的进步。
大模型训练应视为流水线,分为数据工程、预训练、中训、微调和对齐等阶段。每个环节有不同的算力需求和挑战,数据质量至关重要。预训练需处理大量干净数据以确保模型稳定性,中训通过调整数据配比提升能力,微调教会模型理解指令,对齐阶段则使用多种算法优化模型表现。整体训练过程复杂,需关注数据、算力和工程细节。
本文讨论了纳米机器人在监督微调(SFT)中的应用,重点在于数据构造和模型训练过程。模型通过处理用户和助手消息学习生成合适的回复,并强调了在SFT阶段模型如何有效停止输出,提出了线性衰减的学习率策略以提高训练稳定性。
研究表明,在多模态大模型训练中,样本难度比训练范式更为重要。中兴通讯团队首次通过GRPO-only方法,在视觉推理和感知任务中超越传统的SFT+RL范式,提出了PISM和CMAB两种难度量化策略,显著提升了模型性能,验证了难度感知采样的有效性。
机器之心数据服务现已上线,提供高效稳定的数据获取,简化数据爬取流程。
机器之心数据服务现已上线,提供高效稳定的数据获取,简化用户的数据爬取流程。
机器之心数据服务现已上线,提供高效稳定的数据获取服务,帮助用户轻松获取所需数据。
本研究针对中国国有资产和企业(SOAEs)领域特定大型语言模型(LLMs)开发中的关键挑战,提出了一种三阶段框架,解决当前模型容量受限、过度依赖特定监督数据以及推理加速效率低的问题。实验结果表明,该系列模型在维持总体语言能力的同时,显著提高了领域性能,实现了在Rouge-1和BLEU-4分数上的显著提升,展示了为SOAEs LLMs优化的全面性和有效性。
新的扩散模型框架d1通过强化学习提升了大语言模型的推理能力,采用两阶段后训练方法结合监督微调和diffu-GRPO策略梯度,显著改善了数学和逻辑推理任务的表现。
本研究解决了在多模态推理中复制复杂推理特征的挑战。通过在非SFT的2B模型上直接应用强化学习,我们成功实现了“顿悟”瞬间,并在CVBench上达到59.47%的准确率,较基线模型提高约30%。该工作的潜在影响在于为多模态推理的发展提供了新思路,同时揭示了传统方法的局限性。
本文介绍了Open R1项目的开源内容,包括GRPO算法实现、数据生成器和训练代码。Open R1复现了R1的训练流程,并提供了OpenR1-Math-220k数据集,以提升数学推理能力。通过详细的数据生成、过滤和评估过程,Open R1团队确保了数据的高质量和准确性。
清华与CMU团队的研究表明,长思维链(CoT)推理能力可以通过强化学习(RL)实现,监督微调(SFT)并非必需,但能提升效率。研究强调奖励函数对CoT扩展的重要性,并指出模型具备自我纠错能力。未来的研究将集中在模型规模和RL基础设施的改进上。
本文介绍了NL2Fix任务及其数据集Defects4J-NL2Fix,评估了多种大型语言模型在代码修复中的表现。研究发现,语言模型能够有效修复64.6%的错误,最佳模型在基准测试中达到21.20%的top-1精度。通过高质量数据和新方法(如RepairLLaMA),显著提升了自动代码修复的准确性,强调了数据集完整性和训练样本的重要性,以推动代码安全和修复技术的发展。
完成下面两步后,将自动完成登录并继续当前操作。