
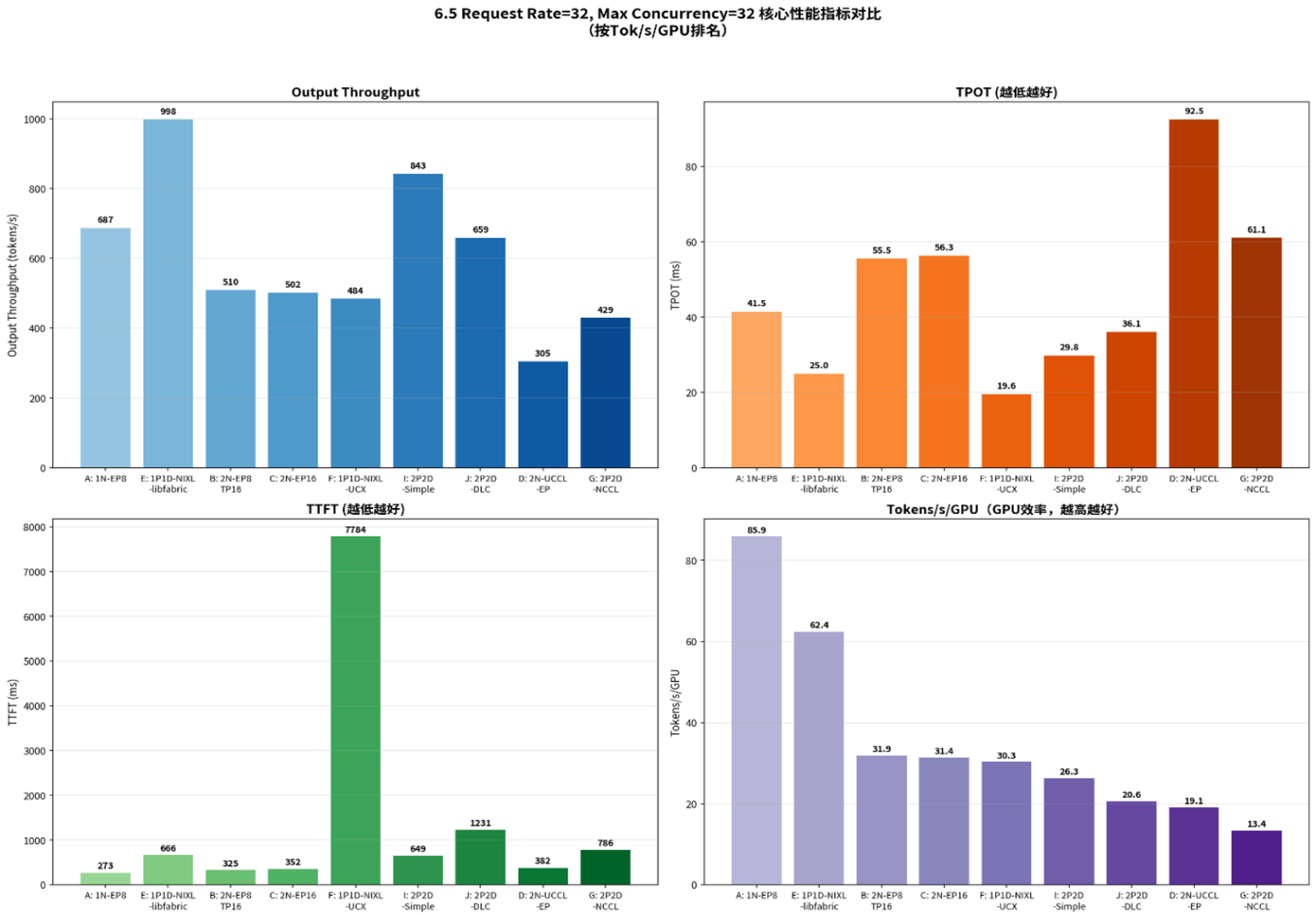
基于SGLang的大模型推理实践——从benchmark方法论到部署方案选型与调优
亚马逊AWS官方博客
·
轻量高性能的 LLM 推理框架,试试 Mini-SGLang
dotNET跨平台
·


KTransformers + LLaMA-Factory + SGLang:低成本本地微调与推理
Home | KVCache.ai
·



浪潮信息元脑R1深度适配SGLang最新版本
全球TMT-美通国际
·

SGLang与Llama.cpp的快速速度测试
DEV Community
·

