激活函数在神经网络中至关重要,决定神经元是否激活,并引入非线性,使网络能够学习复杂模式。常见的激活函数有Sigmoid、ReLU和Softmax,适用于不同任务。选择合适的激活函数能显著提升模型性能。
本文研究了一层隐藏层的神经网络及其修正激活函数,用于解决物理问题。提出了一种修正的 sigmoid 激活函数,并展示了物理信息驱动的数据初始化算法及逐神经元的无梯度拟合方法。数值实验表明,具有修正 sigmoid 函数的神经网络在解决物理问题的准确性上优于传统的 sigmoid 函数神经网络。
逻辑回归是一种用于二分类问题的机器学习工具,通过sigmoid函数输出0到1之间的概率值,适合无异常值的数据集。对于多类分类,使用Softmax函数,是理解分类问题的良好起点。
本文探讨了softmax注意力机制的局限性,提出使用归一化替代softmax以增强自我注意力的鲁棒性。研究表明,sigmoid自注意力在大规模训练中表现优越,且在多个领域的应用效果与softmax相当,推动其作为替代方案的使用。
文章介绍了几种常用的激活函数及其优缺点。Tanh和Softsign将输入转换为-1到1,Sigmoid转换为0到1,Softmax用于多分类,输出总和为1。这些函数有助于归一化和稳定收敛,但可能导致梯度消失和计算复杂。PyTorch中有这些函数的实现。
本文提出了一种新型单变量时间序列预测技术R-HFCM,结合了回声状态网络和最小二乘算法,应用于太阳能预测和电力负载数据,显示出较高的准确性和预测性。同时,研究探讨了模糊认知图在时间序列建模中的应用及未来研究方向。
本文提出了一种新型自适应LSTM网络,优化了神经网络的参数化方法,在Penn Treebank和WikiText-2任务中表现优异,使用更少参数且收敛速度加快。同时,研究了信息瓶颈原理对深度神经网络和二值神经网络的影响,并提出了SST激活函数以提升模型性能。
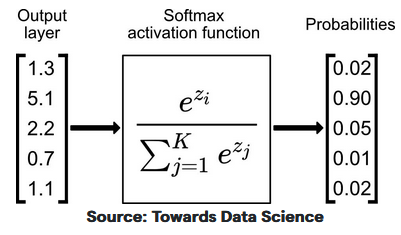
本文介绍了常用的激活函数和损失函数,重点讨论了sigmoid和softmax函数。sigmoid函数的定义和导数被给出,softmax函数用于分类问题,能够将输出值映射到[0, 1]并且和为1。交叉熵损失函数通常与softmax结合使用,简化了反向传播中的计算。
本文提出了一种新的激活函数——稀疏最大函数,能够输出稀疏概率,并给出了其特性及雅可比矩阵的高效计算方法。同时,提出了一个新的平滑且凸函数作为逻辑损失的稀疏最大函数的对应,并发现它与 Huber 分类损失之间的联系。实验结果表明,在多标签分类和自然语言推断的基于注意力机制的神经网络中,采用稀疏最大函数可以获得类似的性能,但具有更精细、更紧凑的注意力焦点。
激活函数常见的有sigmoid、tanh、Relu、Leak Relu、SolftPlus和softmax函数,每个函数有不同的定义和值域,适用于不同情况。
/** * @Author 。。。源 * @Email apple_dzy@163.com * @Blog https://www.findmyfun.cn * ...
完成下面两步后,将自动完成登录并继续当前操作。