
Spark 4.2 has a feature that could retire your vector database
The New Stack
·


介绍 Apache Spark 4.2
Databricks
·
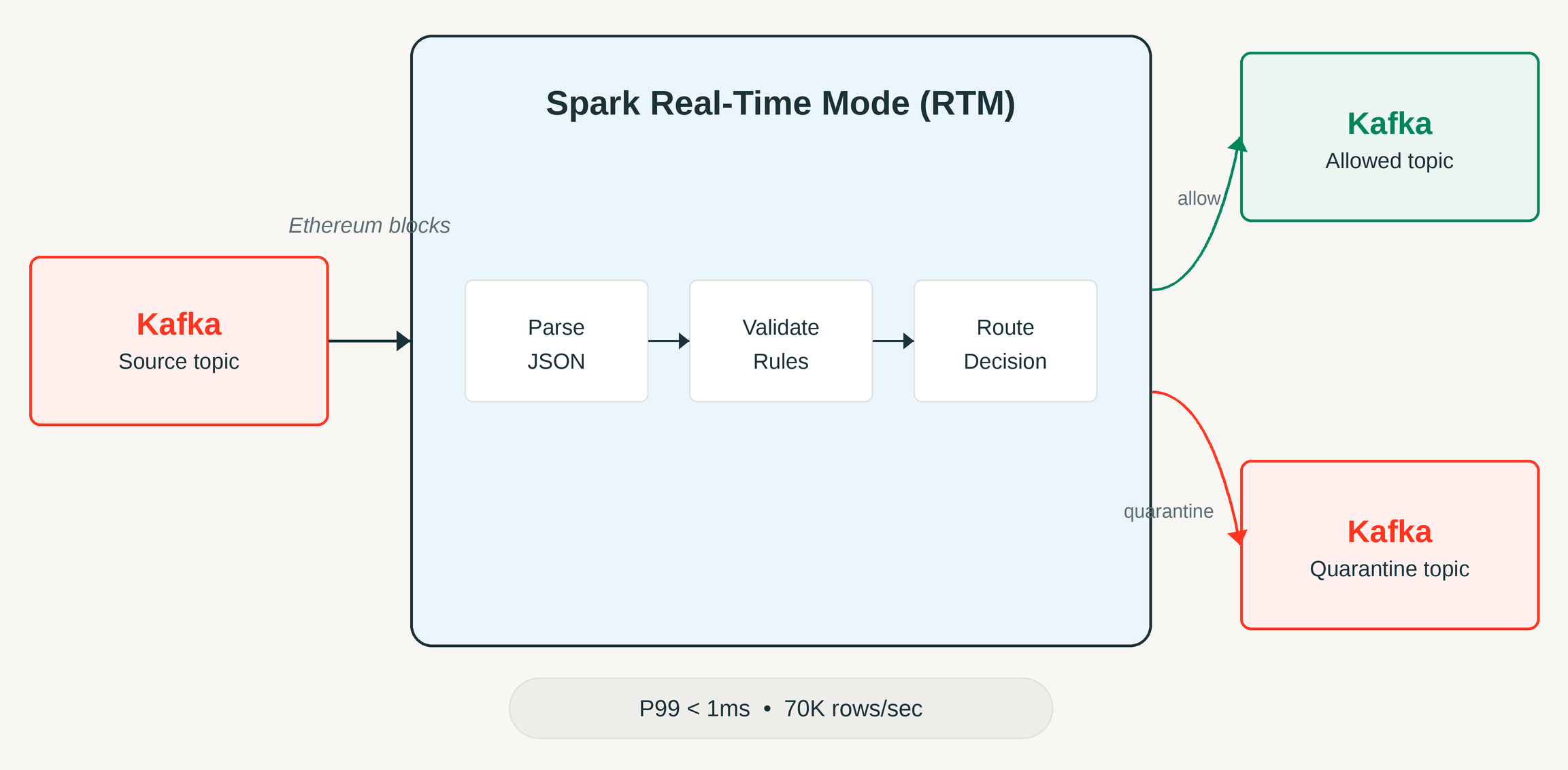
基于Apache Spark实时模式的超快速异常检测
Databricks
·

Meta推出Muse Spark 1.1,且并非免费
The New Stack
·

Muse Spark 1.1现已在AI Gateway上可用
Vercel News
·

Suno推出Spark孵化器计划,以支持独立艺术家并将其纳入AI生态系统
The Verge
·
Databricks ETL迁移决策框架
Databricks
·

NVIDIA、KRAFTON、NC及现任《英雄联盟》冠军T1在韩国PC房庆祝RTX Spark
NVIDIA Blog
·

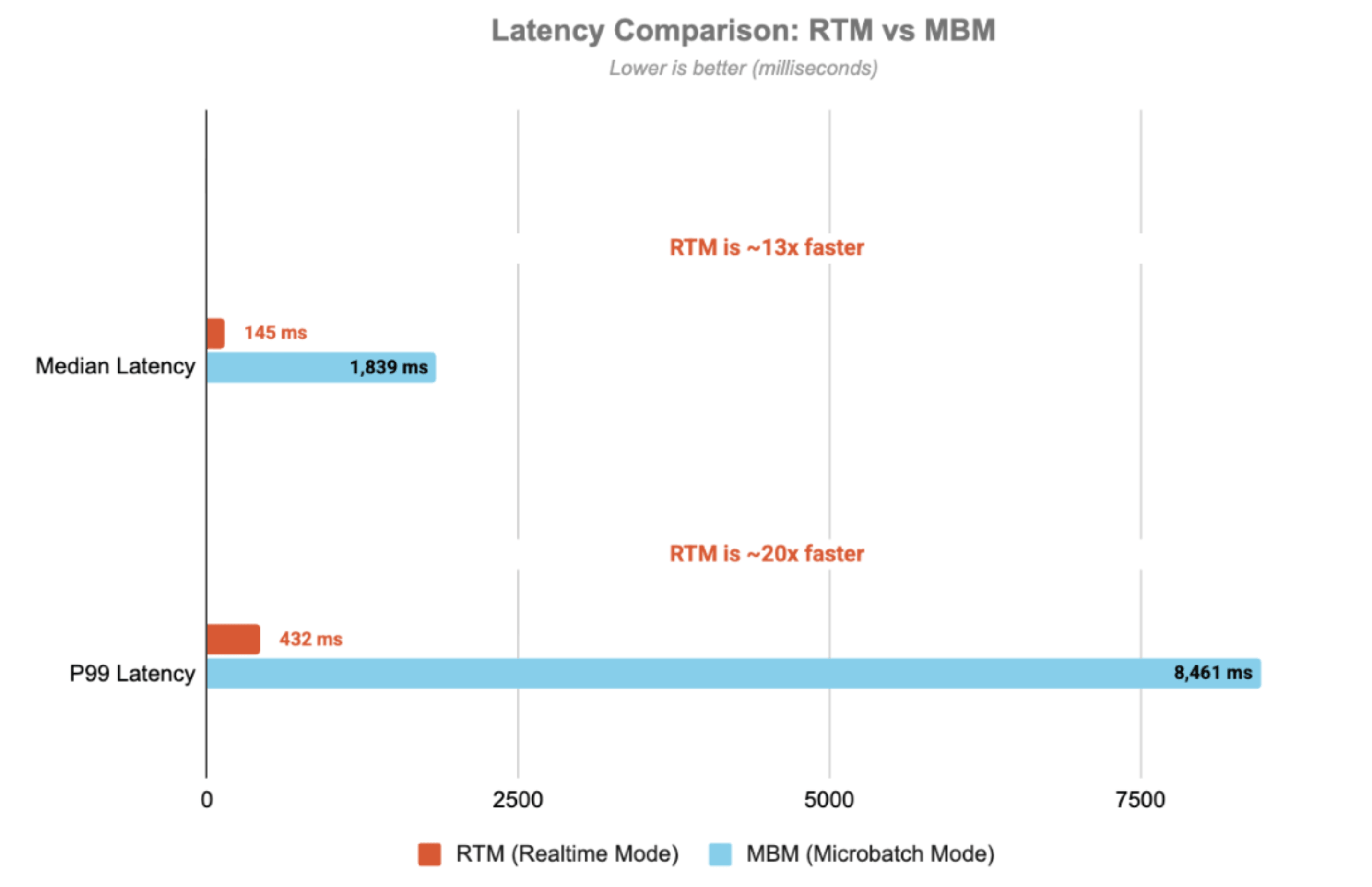
游戏行业中的Apache Spark实时模式:更好的实时会话处理方式
Databricks
·
