

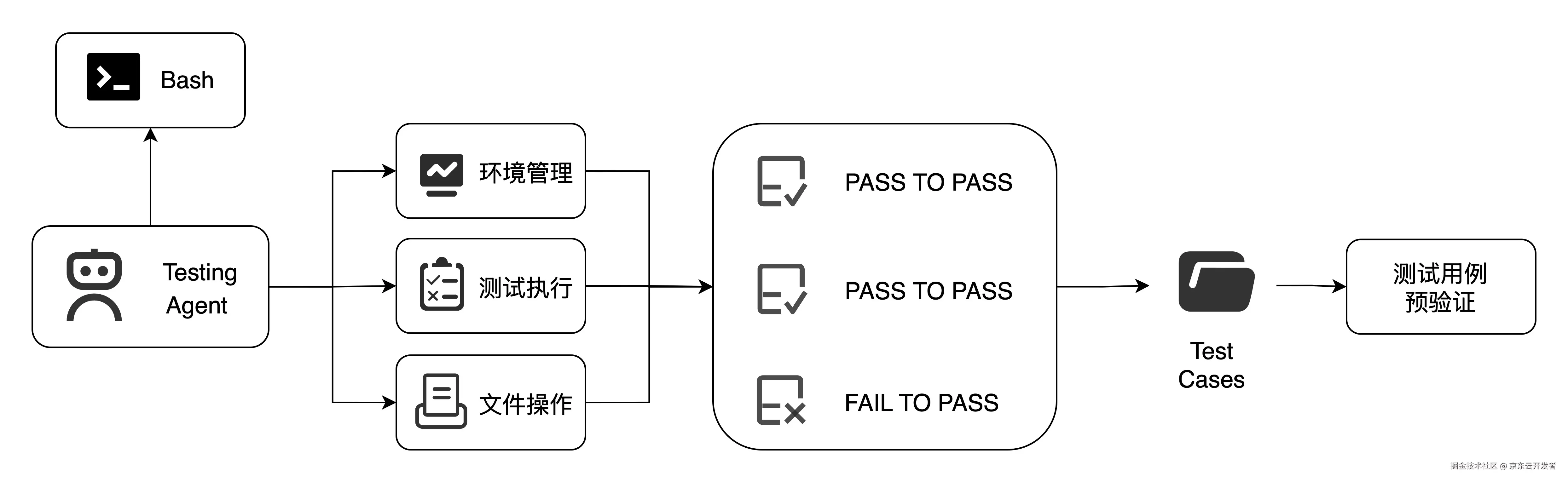
JoyCode:SWE-bench Verified打榜技术报告
京东科技开发者
·


使用TeamCity和SWE-bench测试AI编码代理
The JetBrains Blog
·


开源Refact.ai代理在SWE-bench Lite中自主实现#1
DEV Community
·

SWE-bench与SWE-bench Verified基准
DEV Community
·

细看 Claude 3.7 两个重要的 Benchmark:SWE-Bench & TAU-Bench
bang's blog
·
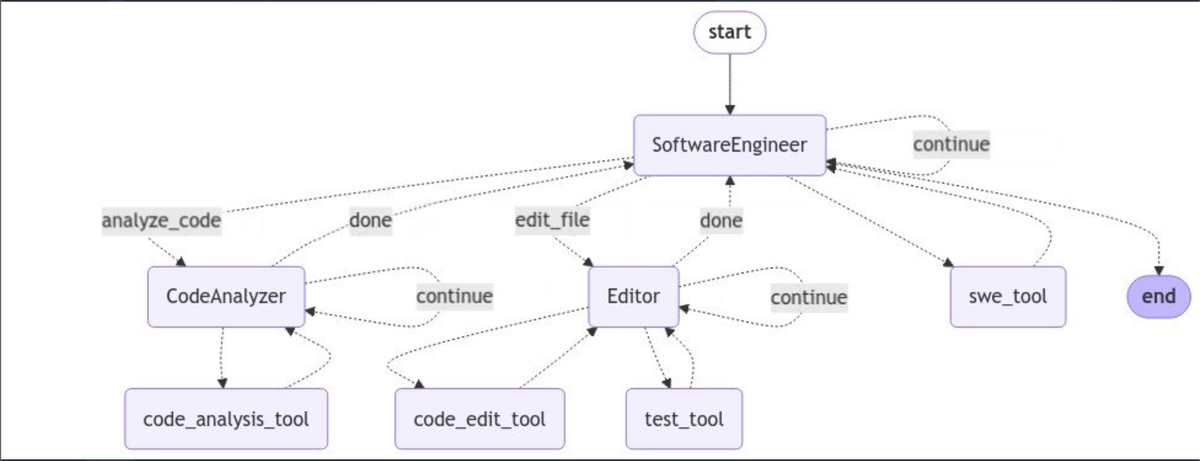
Composio的SWE代理在SweBench上利用LangGraph和LangSmith取得48.6%的分数,推动开源发展
LangChain Blog
·


介绍SWE-bench验证
OpenAI
·

