
Fish TTS API 对接说明
静觅
·


如何训练AI语音开发模型?从数据准备到三层优化的实操路径
实时互动网
·

哪些AI语音开发平台收费低?了解最省钱的选型组合
实时互动网
·
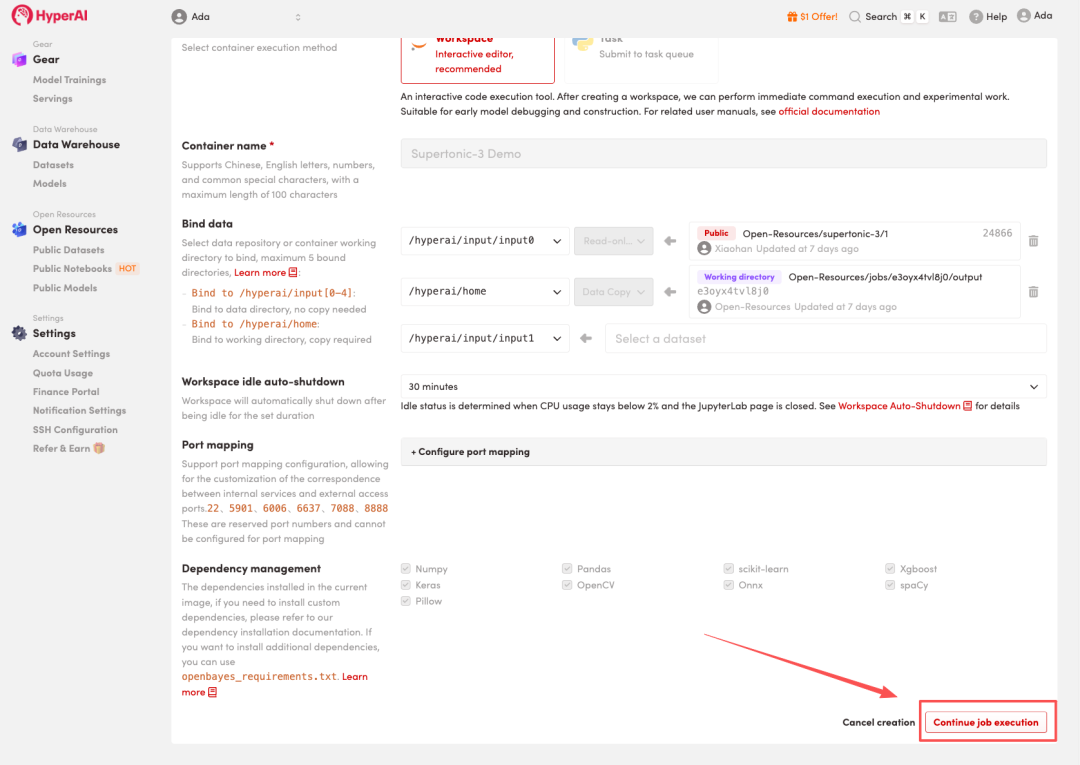



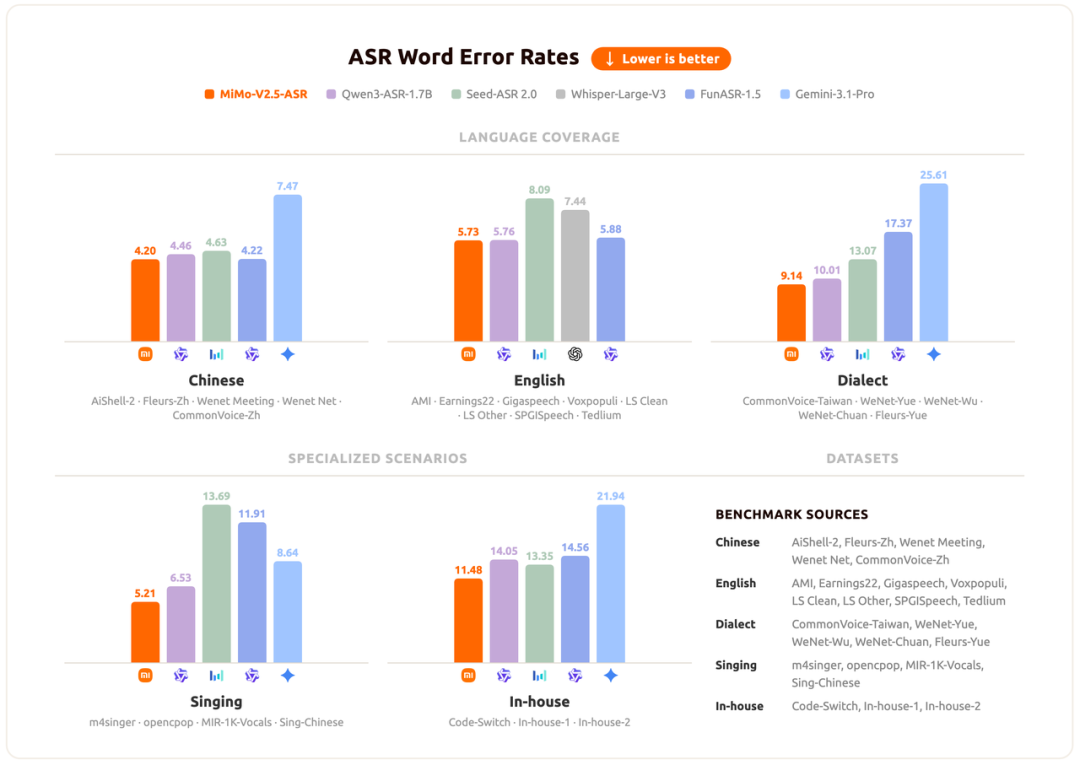
MiMo-V2.5-TTS-Series + ASR 正式发布
小米云技术
·