在 MySQL 中,utf8 不支持部分 Emoji,而 utf8mb4 支持。默认的 utf8_general_ci 和 utf8mb4_general_ci 排序规则不区分大小写。要实现大小写敏感查询,可以修改排序规则或使用 BINARY 关键字。在 ThinkPHP 中,可通过 whereRaw 方法执行原生查询以确保大小写敏感匹配。
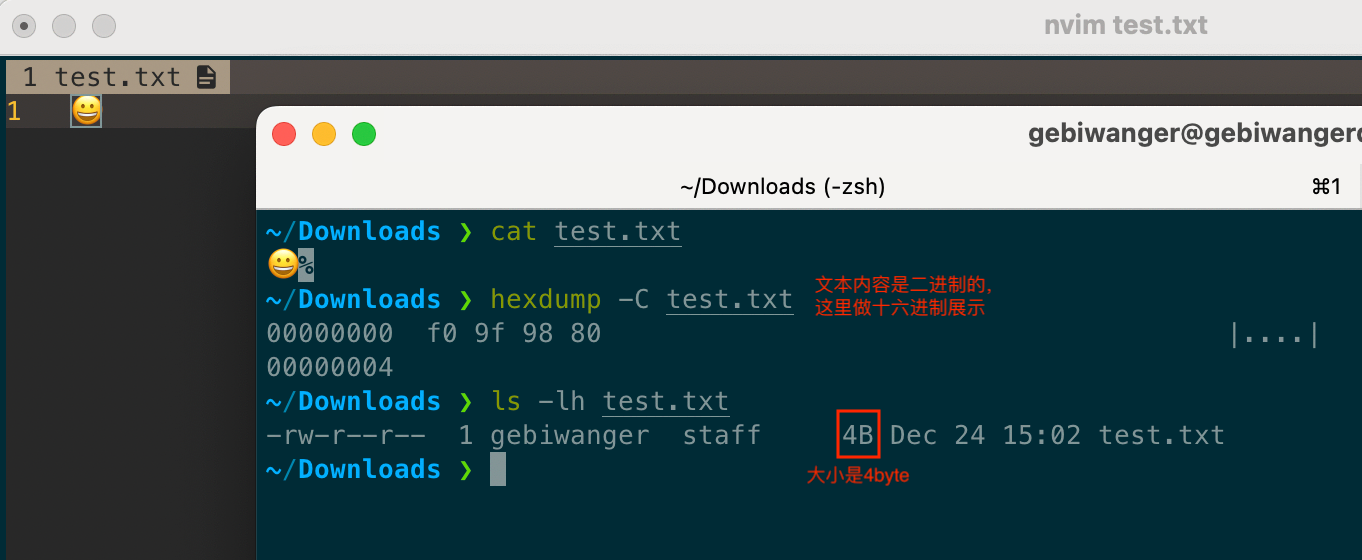
MySQL的utf8和utf8mb4的主要区别在于字节数。utf8最多支持3字节,无法存储表情符号;而utf8mb4支持4字节,能够存储表情符号和补充Unicode字符。因此,建议始终使用utf8mb4以避免相关问题。
本文介绍了字符编码的相关知识,包括Unicode、UTF-8/16/32的介绍,文本二进制存储和URL编码等场景,以及内存中字符串的编码格式。文章还提到了不同编程语言在内存中使用的编码方式,以及选择不同编码方式的考虑因素。
一、报错回顾 将emoji文字直接写入SQL中,执行insert语句报错; [Err] 1366 – […]
修复 nodejs/performance#3 基准 CI: https ://ci.nodejs.org/view/Node.js%20benchmark/job/benchmark-node-micro-benchmarks/1219/ 测试结果: util/text-decoder.js type='ArrayBuffer' n=100 len=16384...
由于mysql的历史原因.其UTF-8是一个残缺品.最多支持3字节编码的UTF-8编码. 而要支持4字节的UTF-8编码,实际要把字符集编码修改为utf8mb4. 如果表已经通过存在,修改风险比较大. 那我们该怎么办呢.
虽然这个问题一直在接受新知识,同时不断更正自己对字符集的理解. 但是时间久了,难免自己的知识理解又模糊了....
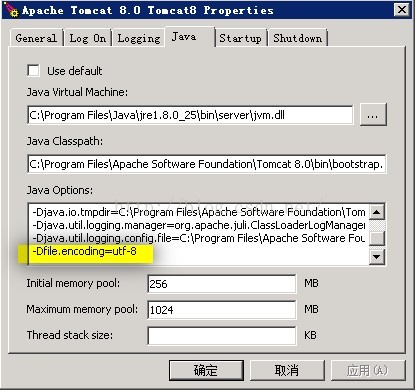
对于tomcat服务器上的utf8文件乱码的问题,找到以下解决方法,特此记之: 问题表现 • jsp文件不乱码; • 只有html等静态资源文件乱码; • html文件charset设置正确; • 需要转为utf-8-bom编码才可以正常访问;
在Tomcat服务器上解决UTF-8文件乱码问题的方法包括:确保HTML文件的charset设置正确,并将文件转换为UTF-8-BOM编码。Linux用户可通过设置环境变量`export LANG=zh_CN.UTF-8`来解决,Windows用户需在`catalina.bat`中设置`-Dfile.encoding=utf-8`。
在Tomcat服务器上解决UTF-8文件乱码问题的方法包括:确保HTML等静态资源文件编码为UTF-8-BOM,Linux设置环境变量为zh_CN.UTF-8,Windows需在catalina.bat中配置JAVA_OPTS为utf-8。问题可能与SiteMesh过滤器和操作系统初始值有关。
对于文本文件的编码,时常会有一些误区和不理解,比如:Unicode 是什么编码、字节和编码是什么关系等。本文将依次渐近的,从 ASCII/ Unicode 介绍到 UTF8/16/32,以及文本二进制存储和 URL 编码/多次编码等场景。
承上篇提到的 utf8 問題,今天就來說明一下 utf8 和 utf8mb4 其中的差異與淵源 有一句話是這樣講的 MySQL 中的 utf8 並不是真正的 utf8 出處就不可考了,之前上 DK 的課也有聽到這一個
在刚刚开始学PHP时,遇到过这样一个问题,在本地运行得好好的一段代码在SAE上则获取cookie失败,这让我百思不得其解。搞了很长时间之后也找不到到底是哪出了问题,于是我将cookie换成了session试了一下,结果本地运行也出了问题,报了这个错误: Cannot modify header information - headers already sent...
编程难免遇到需要转换Unicode或UTF8到字符串的情形。例如在vCard里面就有 X-ESI-CATEGORIES;CHARSET=UTF-8;ENCODING=QUOTED-PRINTABLE:=E6=9C=AA=E8=AE=BE= =E5=AE=9A=E7=BE=A4=E7=BB=84 我们关注这一句的后面部分,使用的是UTF8编码。我想
完成下面两步后,将自动完成登录并继续当前操作。