Voxtral TTS是Mistral AI推出的开源文本转语音模型,支持九种语言,能够在三秒音频基础上克隆声音,具有70毫秒的低延迟和9.7倍的实时因子,适合实时对话应用。用户可通过Mistral API或自托管方式使用,提供灵活的商业和非商业使用选项。
Mistral发布了Voxtral-4B-TTS-2603模型,旨在提升多语言语音生成的自然度和效率。该模型结合了语义自回归和声学流匹配,支持低延迟本地运行,展现出良好的泛化能力。
Mistral AI于2026年2月开源了Voxtral Mini 4B Realtime 2602模型,支持13种语言的实时语音转录,延迟低于500毫秒,适合轻量化应用,并可在边缘计算单元上部署,提升语音识别的精度与效率。
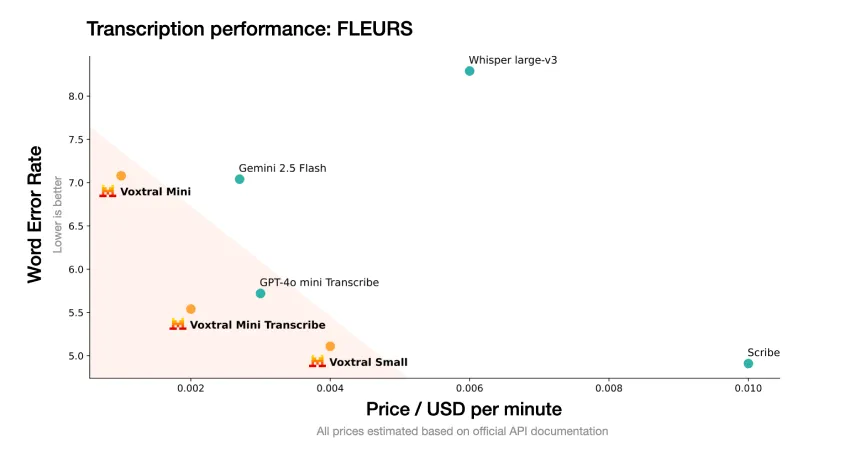
Mistral AI 于 2 月 4 日发布了 Voxtral Transcribe 2 系列语音转文字模型,包括面向批量处理的 Voxtral Mini Transcribe V2 和实时转录的 Voxtral Realtime。Voxtral Realtime 具有低于 200 ms 的延迟,支持 13 种语言。定价方面,Mini Transcribe V2 每分钟 0.003 美元,Realtime 每分钟 0.006 美元。
总部位于巴黎的Mistral AI推出了两款语音转文本模型,强调快速、准确和低成本,适合处理敏感数据。Voxtral Transcribe 2系列支持本地运行,满足医疗和金融等行业需求。Mistral重视隐私保护,预计到2026年AI转录将获得用户信任。
Mistral发布了Voxtral,一个大型语言模型,旨在提升语音识别能力,超越简单转录。Voxtral Mini和Small两个版本的模型权重已开放。该模型结合了传统ASR系统的高效转录与LLM的语义理解,支持多种语言,具有32K的上下文,能处理长达30分钟的音频,适用于企业客户的多种高级功能。
Mistral AI 发布了开源音频模型 Voxtral,提供 24B 和 3B 两个版本,旨在解决语音智能市场的痛点。Voxtral 支持多语言和长文本处理,具备内置问答功能,性能优于现有开源模型,成本低,适合多种应用场景,推动语音交互普及。
Mistral AI发布了Voxtral音频模型,提供24B和3B两个版本,旨在解决语音智能市场的痛点。该模型支持多语言、长文本处理和问答功能,性能优于现有开源模型,成本低,适合多种应用场景,推动语音交互普及。
完成下面两步后,将自动完成登录并继续当前操作。