
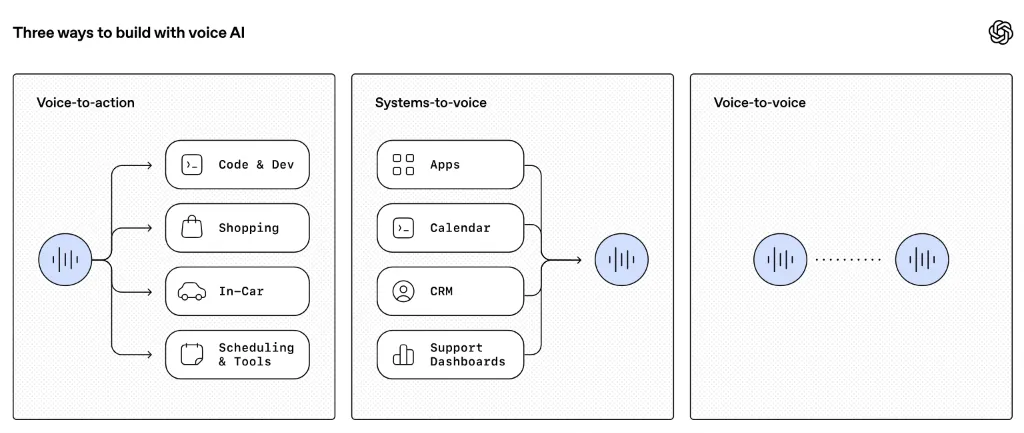

使用Amazon SageMaker Hyperpod Cluster部署whisper模型
亚马逊AWS官方博客
·



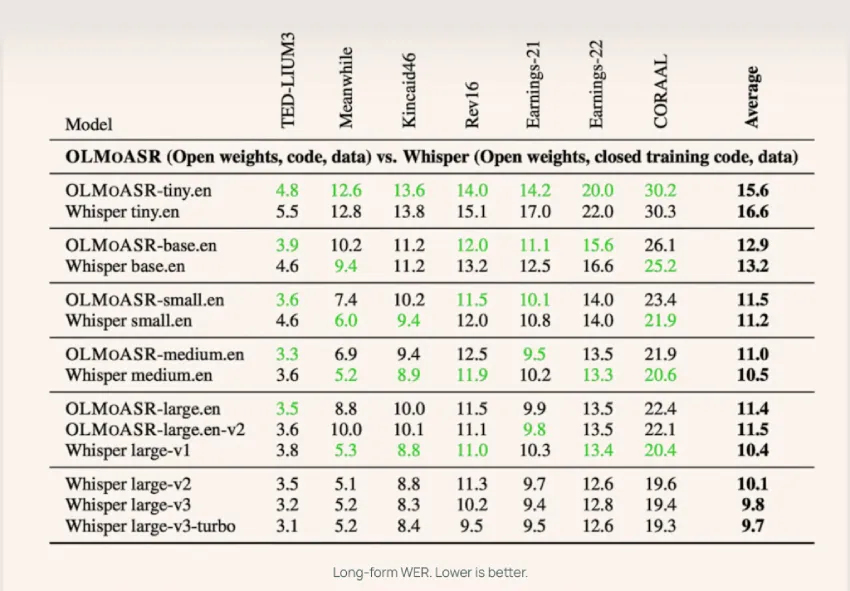


通过提示Whisper提高逐字转录和端到端错误检测的准确性
Apple Machine Learning Research
·

高质量转录低噪声双通道电话录音
DEV Community
·

与Claude和Gemini合作优化whisper模型。主要难点在于数据格式化,目前已开始使用label-studio。
DEV Community
·
