


多年来,Apache Cassandra 将这项工作交给了你的团队——而6.0版本将其收回
The New Stack
·

Apache®软件基金会宣布新的顶级项目
The Apache Software Foundation Blog
·
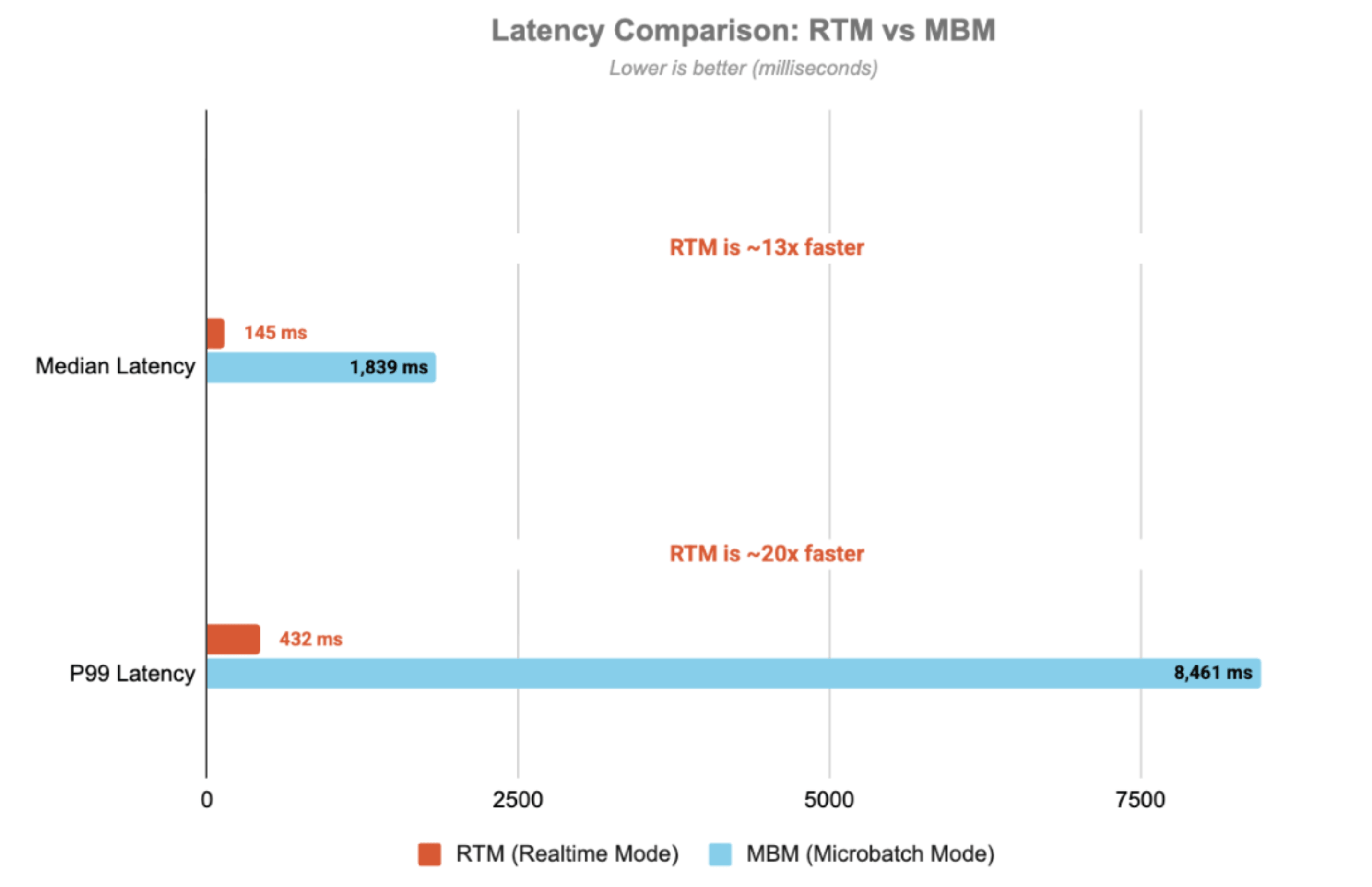
游戏行业中的Apache Spark实时模式:更好的实时会话处理方式
Databricks
·
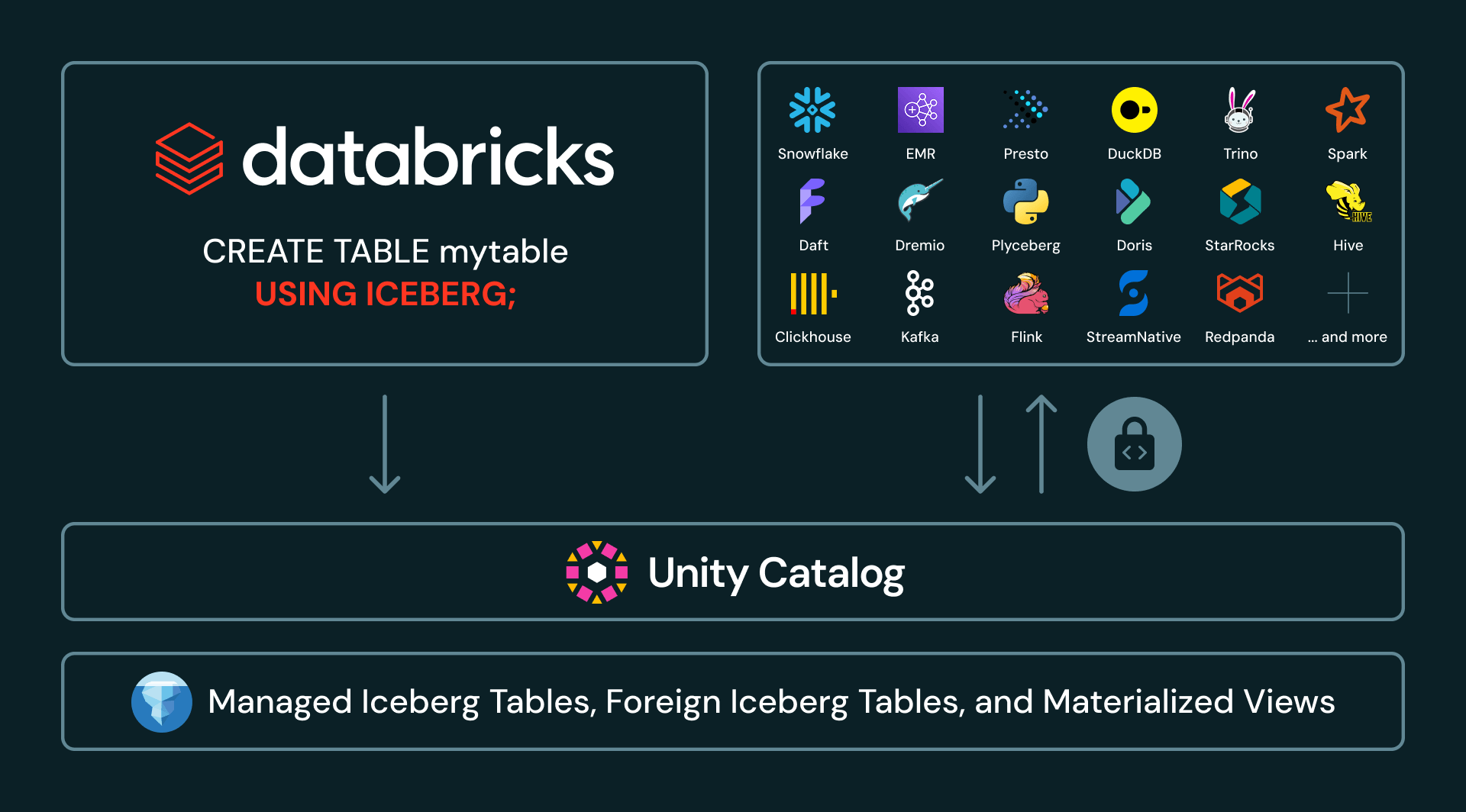
Unity Catalog 与 Apache Iceberg™ 的下一个时代
Databricks
·

伊丽莎白·加雷特·克里斯滕森:使用Apache AGE在Postgres中进行图形查询
Planet PostgreSQL
·

开源如何自我治理:Apache STeVe v3背后的故事
The Apache Software Foundation Blog
·

Apache SeaTunnel 创新加速 :AIDLC 方法论实践
亚马逊AWS官方博客
·

Apache Geode 2.0,第二部分:为现代Java时代重建分布式系统
The Apache Software Foundation Blog
·

在mssql-python中引入Apache Arrow支持
Python
·

ASF项目聚焦:Apache Iceberg
The Apache Software Foundation Blog
·

公共CA的clientAuth EKU退役:Apache软件部署者需要知道的事项
The Apache Software Foundation Blog
·
