

Fizz通过Databricks SQL加速电商分析
Databricks
·

在Databricks上构建移动游戏的A/B测试分析框架
Databricks
·
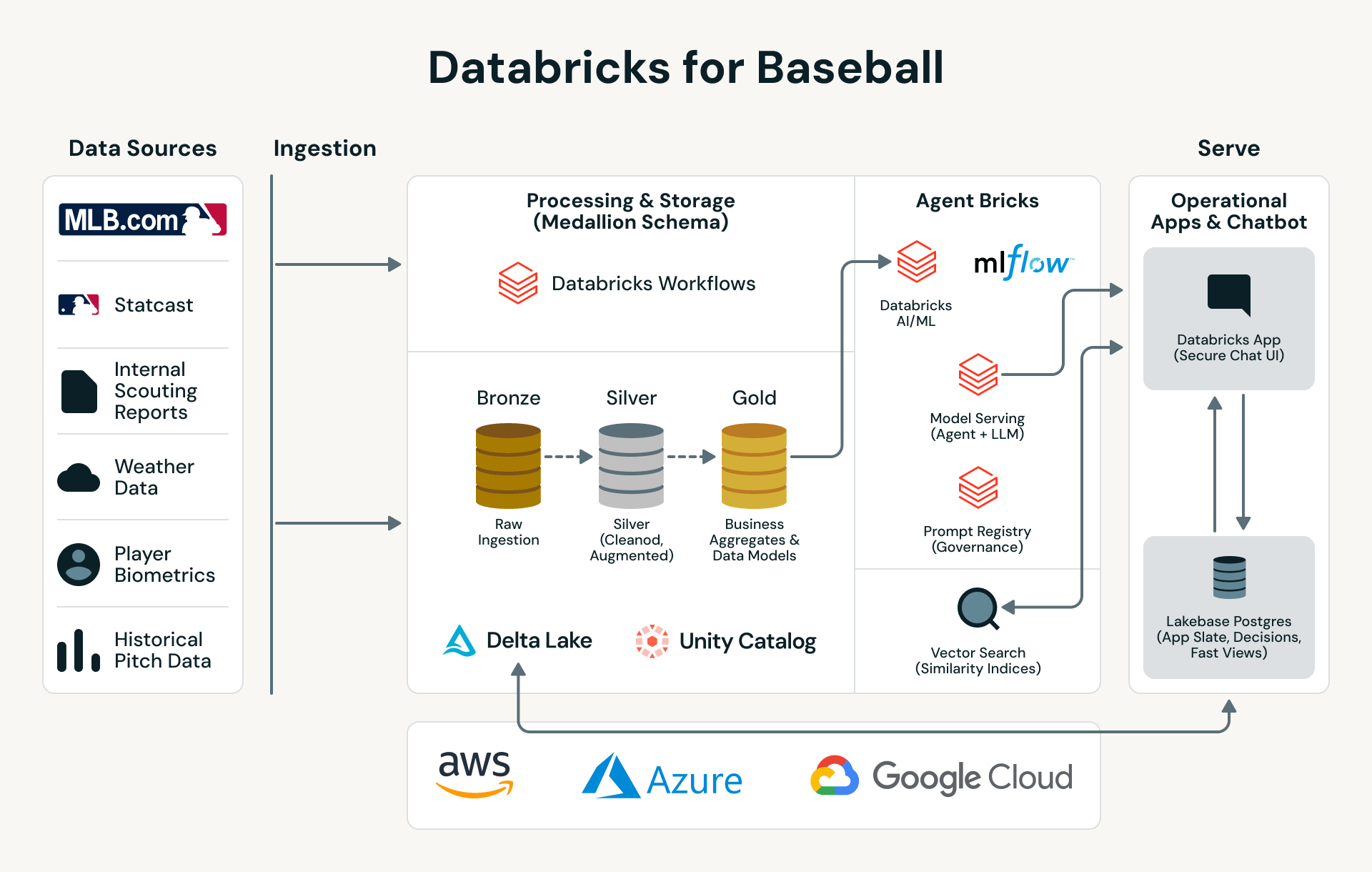
Databricks如何帮助棒球队利用数据和人工智能获得优势
Databricks
·
Databricks被评为Gartner® Peer Insights™分析与商业智能客户选择
Databricks
·

谷歌云使用案例:企业如何在GCP上利用Databricks运行数据与AI
Databricks
·

Databricks宣布Lakewatch:新型开放式智能SIEM
Databricks
·
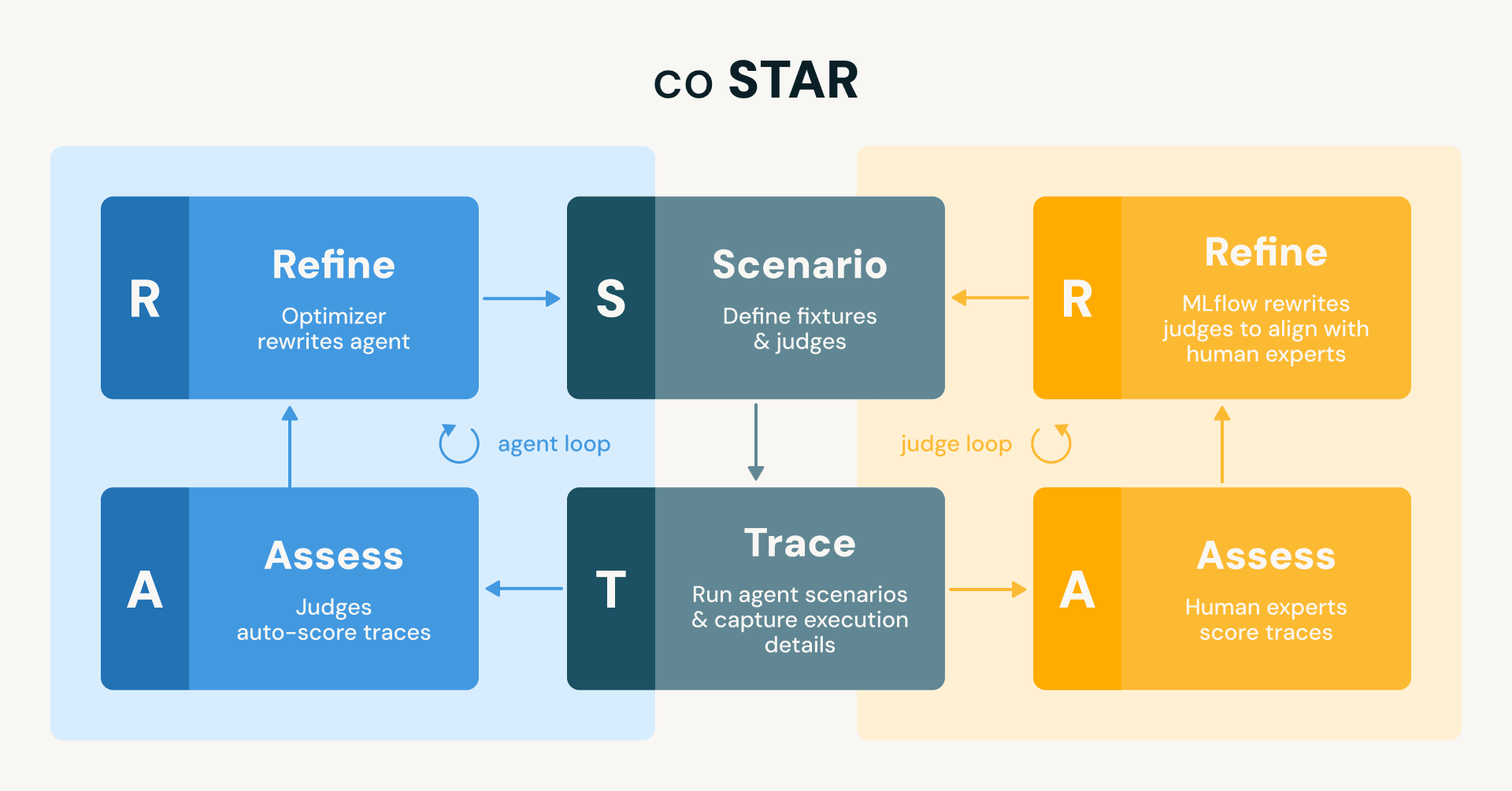
coSTAR:我们如何在Databricks快速交付AI代理而不出错
Databricks
·
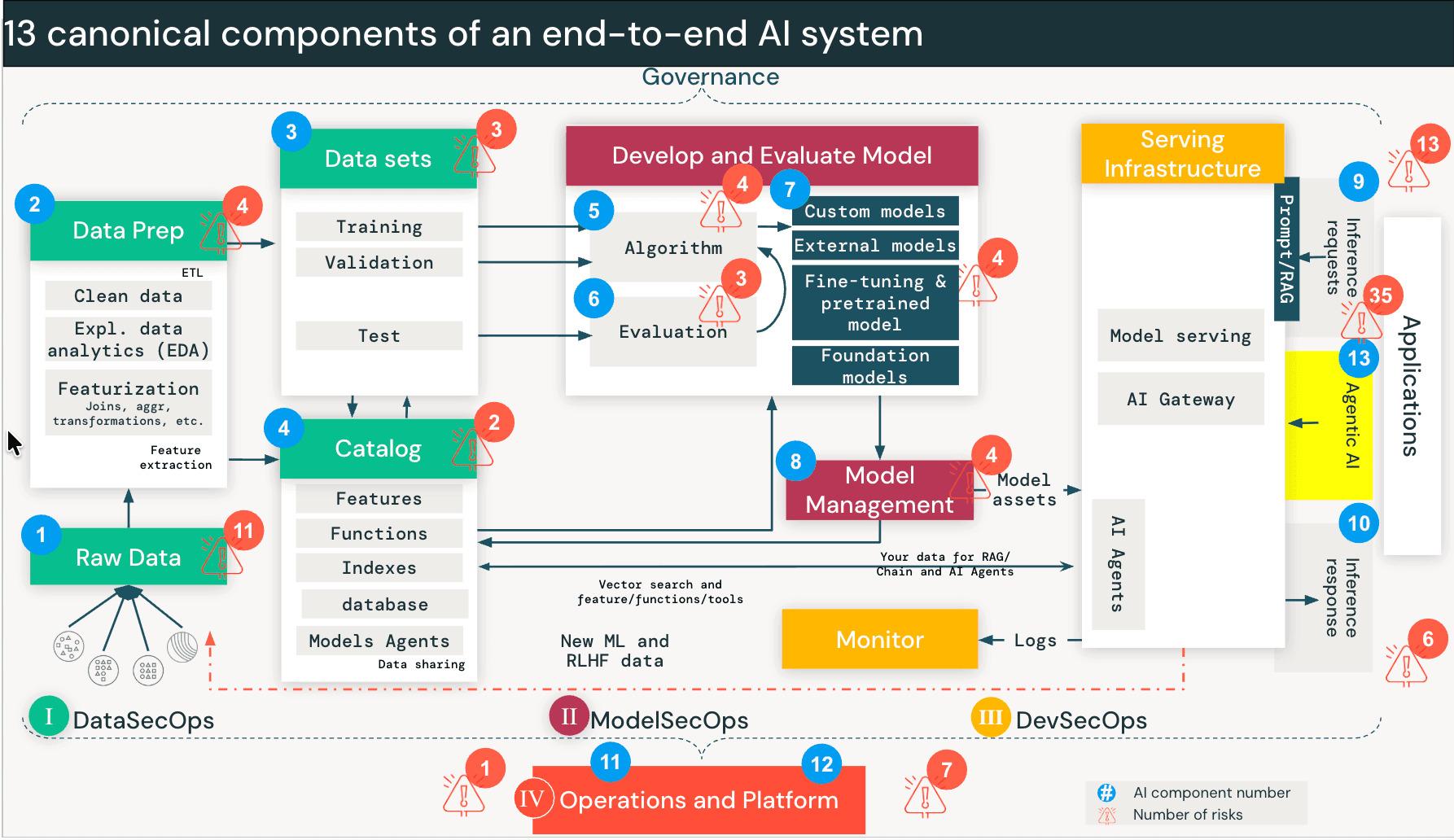
自主AI安全:Databricks AI安全框架(DASF v3.0)中的新风险与控制措施
Databricks
·

多云挑战、智能负载均衡与人工智能驱动的工作流:Databricks在SRECon 2026的分享
Databricks
·
介绍AI Runtime:在Databricks上可扩展的无服务器NVIDIA GPU用于训练和微调
Databricks
·
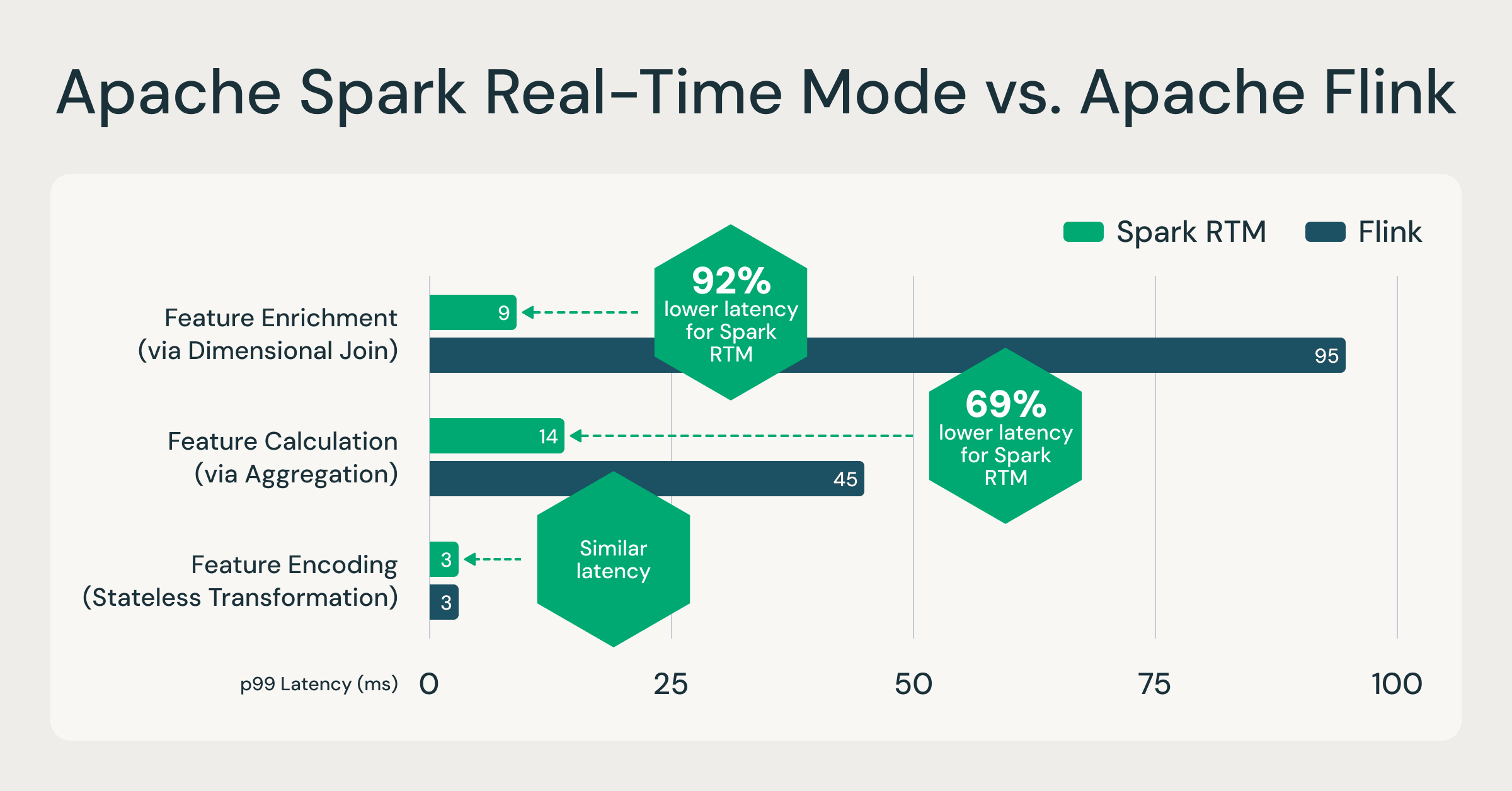
宣布Databricks上Apache Spark结构化流实时模式的正式发布
Databricks
·
如何将Apache Airflow®迁移到Databricks Lakeflow Jobs
Databricks
·
通过Agent Bricks和Databricks Apps向业务用户交付高质量的企业AI代理
Databricks
·
GCI与Databricks合作为客户和业务创造价值
Databricks
·
Azure Databricks中的无服务器工作区现已正式上线
Databricks
·
降低Databricks上AI代理的提示注入风险
Databricks
·

您的Databricks指南:HIMSS26
Databricks
·

Databricks收购Quotient AI以增强AI代理评估能力
Databricks
·
超越资源配置:开发者的Databricks Lakebase自动扩展指南
Databricks
·
