

171个“已批准”却迟迟未实现的提案:Go语言的十年“欠账清单”
Tony Bai
·
别再往 Go 里塞 Java 了:拆解 spf13 的 Idiomatic Go 信仰
Tony Bai
·

TypeScript 7.0 正式发布:Go 原生重写,构建提速 8-12 倍
icodex - 个人网站
·
2026-07-12-前端与AI技术周报
icodex - 个人网站
·
微软支持Go语言用于AI代理,追赶Google — OpenAI和Anthropic落后
The New Stack
·


Acer Swift Go 16是一款性价比高的笔记本,售价900美元
The Verge
·
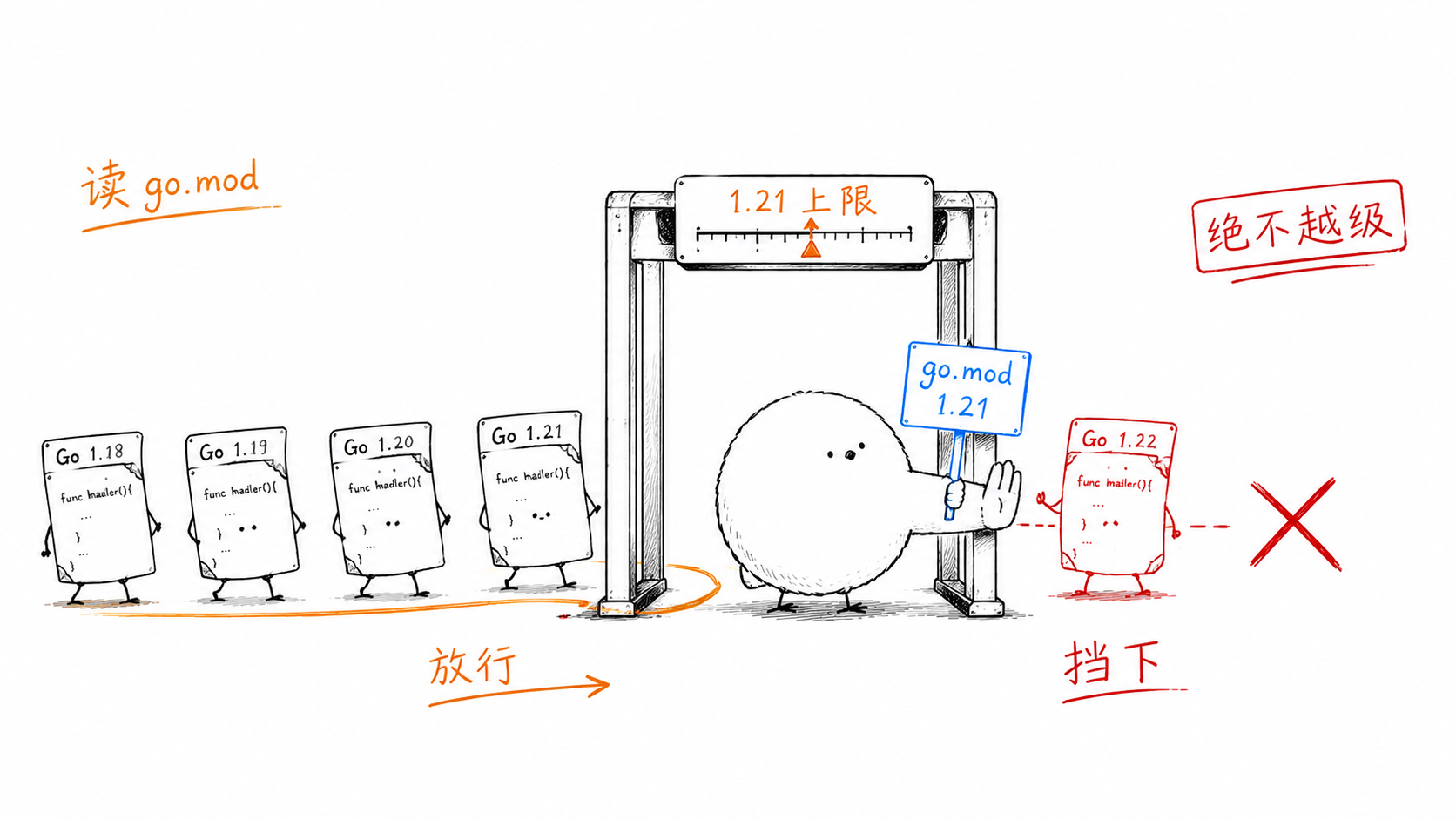
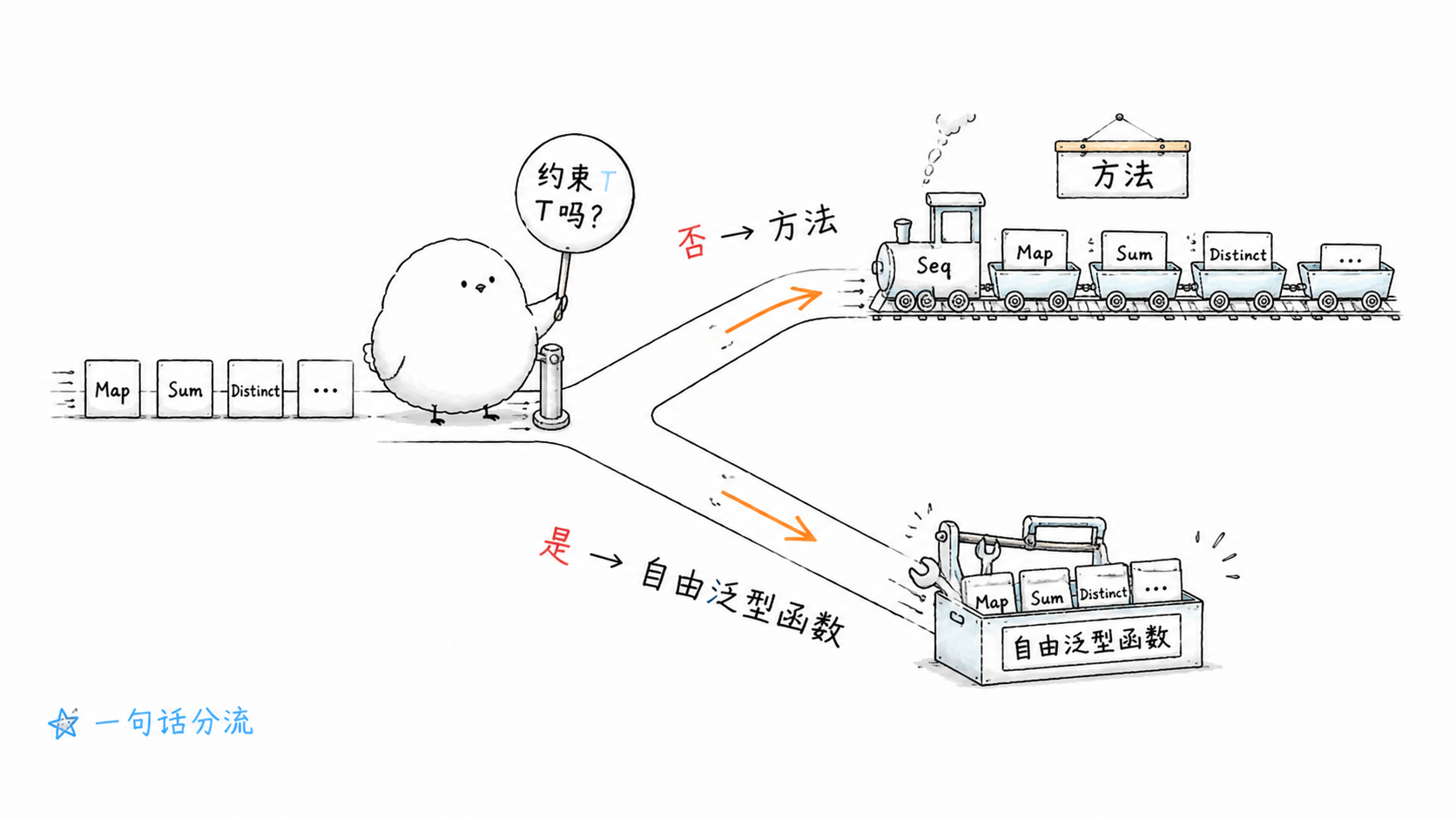

在 AI 编码时代,为什么我们依然选择 Go 而不是 Rust?
Tony Bai
·

Java微服务能否与Go一样快速?2026年基准测试更新
insidejava
·
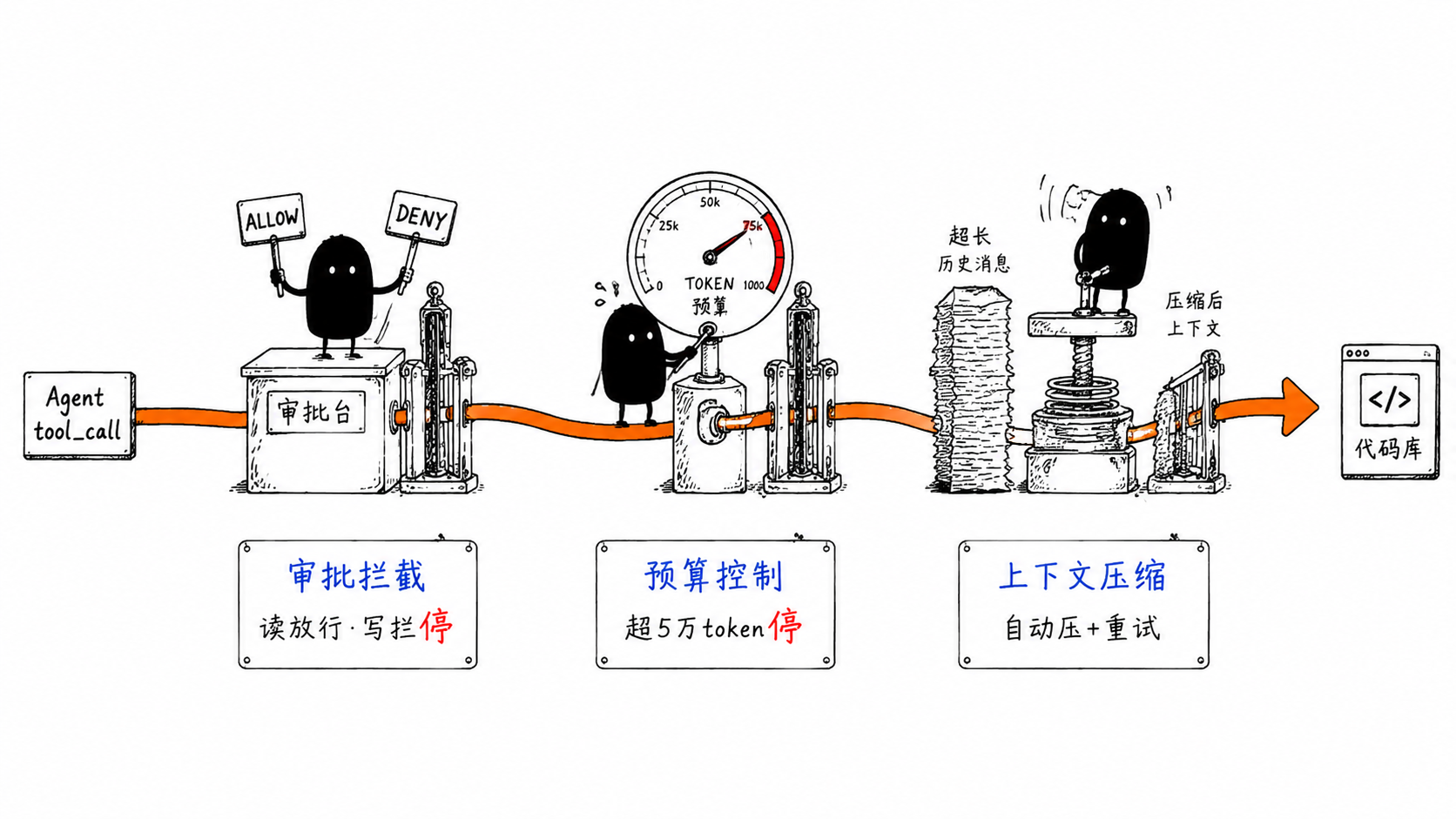

如何在Go中构建基于PostgreSQL的任务队列
freeCodeCamp.org
·
别把 Go 写成 Java:毁掉项目从过度架构开始
Tony Bai
·

