


肖恩·托马斯:期待Postgres 19:检查点控制
Planet PostgreSQL
·
克里斯托弗·温斯莱特:Postgres 19 压缩:从 pglz 到 LZ4
Planet PostgreSQL
·
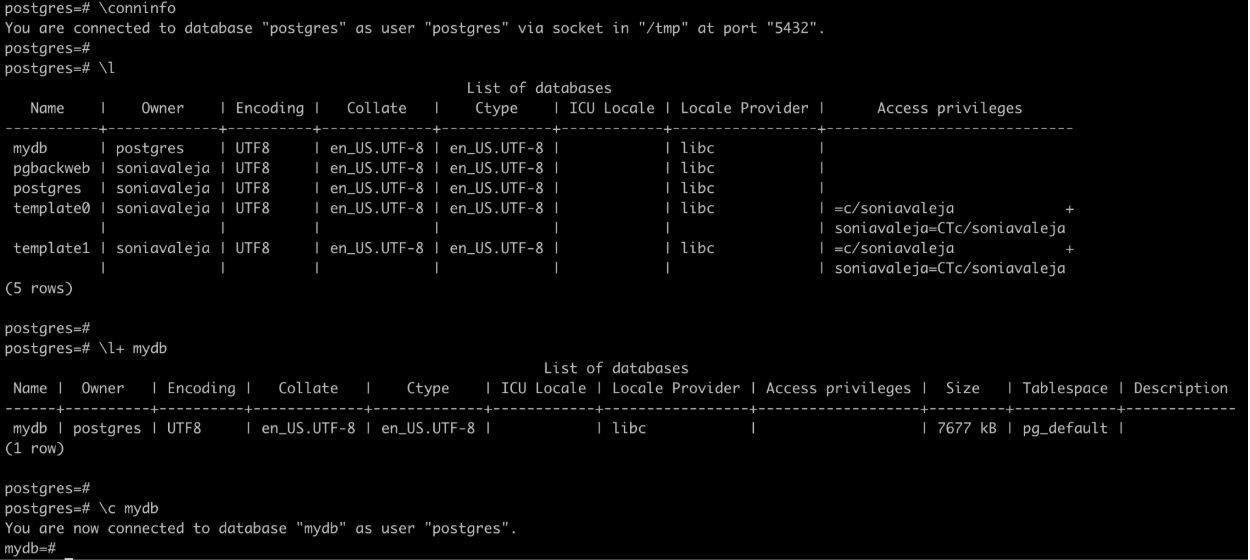
每天节省时间的PostgreSQL元命令
Percona Database Performance Blog
·

让768台服务器看起来像1台
PlanetScale - Blog
·

Jimmy Angelakos:LinkedIn Live:修复PostgreSQL中的错误SQL
Planet PostgreSQL
·
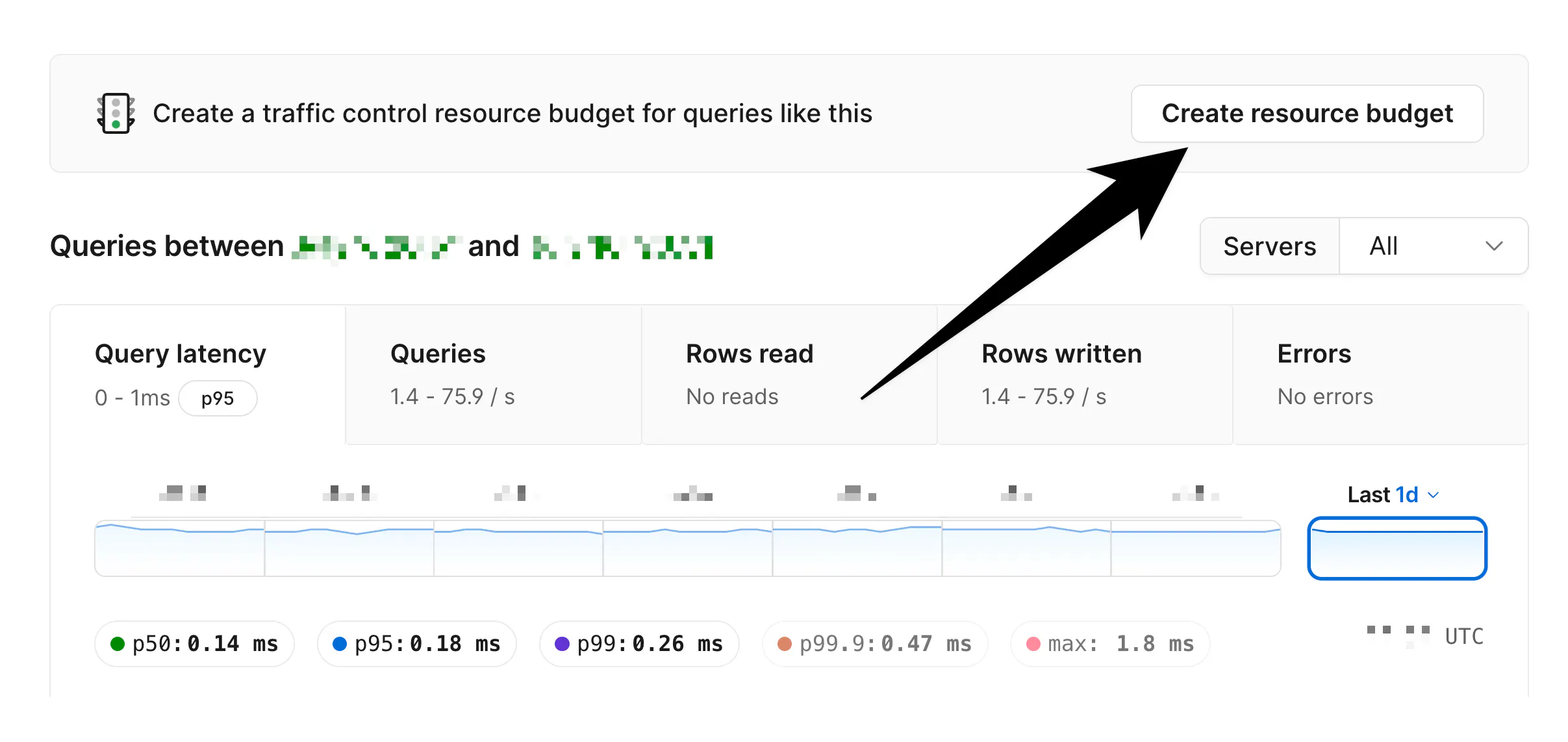
当Postgres查询规划器失控时
PlanetScale - Blog
·


维博尔·库马尔:PostgreSQL、AI治理与C.A.L.M.平台测试
Planet PostgreSQL
·
