

Python Hub Weekly Digest for 2026-04-19
Python Hub Weekly
·

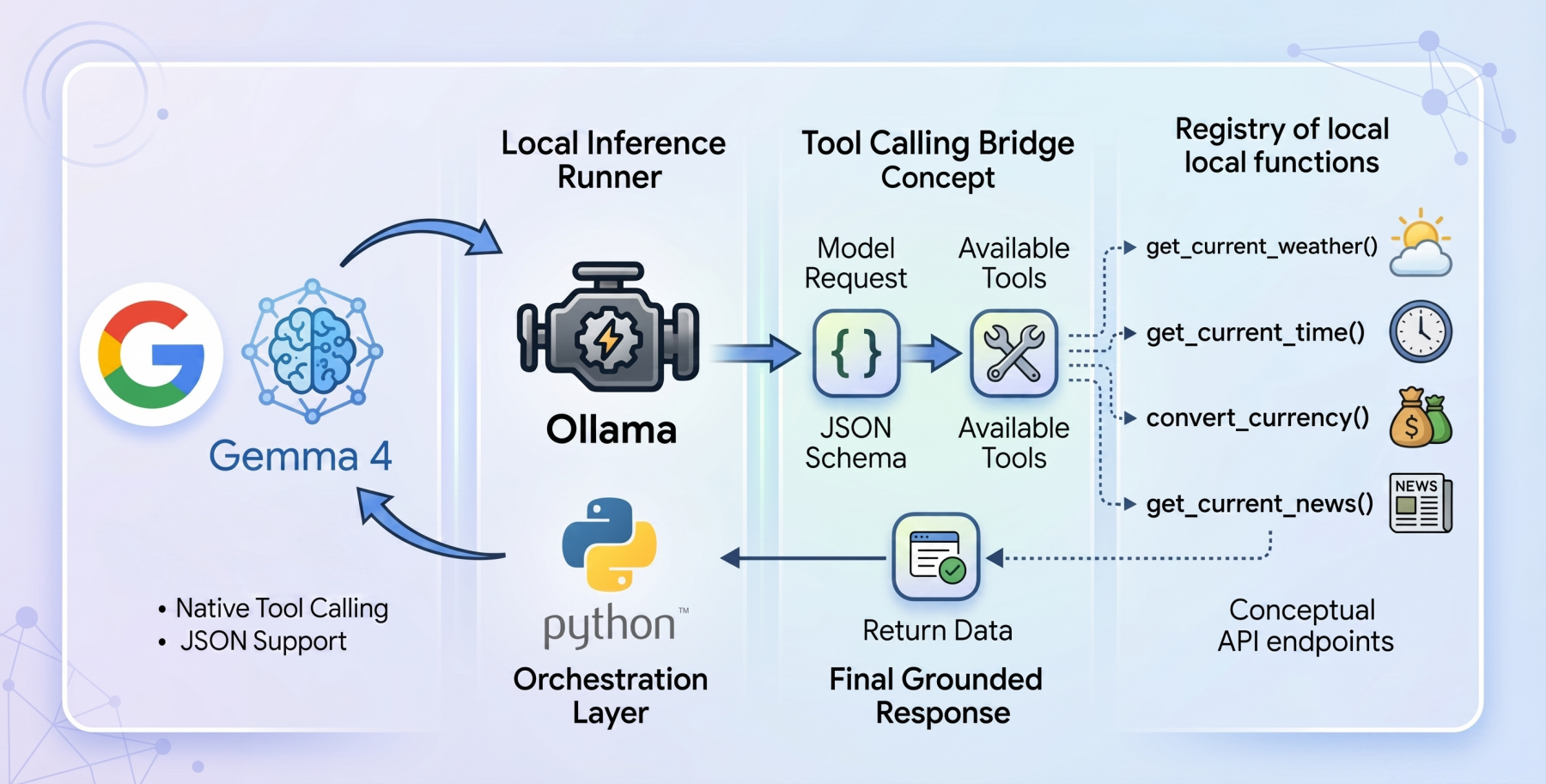
如何使用Gemma 4和Python实现工具调用
MachineLearningMastery.com
·

Python中的高效数据处理:批处理与流处理管道解析
freeCodeCamp.org
·
2026年4月12日Python中心周刊摘要
Python Hub Weekly
·

我所理解的Python元模型 - Artech
Artech
·

Python 潮流周刊#146:CPython 引入 Rust 的进展
豌豆花下猫 | Python猫
·
![如何在Python中构建基于定位的原油交易策略 [完整手册]](https://cdn.hashnode.com/uploads/covers/5e1e335a7a1d3fcc59028c64/c18002cf-6519-4b76-b068-3b443cb0f347.png)
如何在Python中构建基于定位的原油交易策略 [完整手册]
freeCodeCamp.org
·


