
苹果公司与罗切斯特大学联合开发生成式空间音频模型,进一步提升沉浸式体验
内容提要
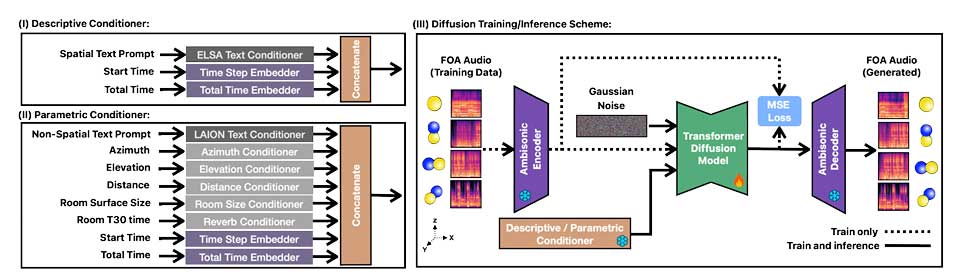
ImmerseDiffusion是一种新型生成音频模型,能够根据空间、时间和环境条件生成高质量的3D沉浸式音景。该模型专注于一阶Ambisonics音频,支持描述性和参数化模式,适用于电影和游戏等场景,表现出色,具有广泛应用前景。
关键要点
-
ImmerseDiffusion是一种新型生成音频模型,能够生成高质量的3D沉浸式音景。
-
该模型专注于一阶Ambisonics音频,适用于电影和游戏等场景。
-
现有生成式音频模型通常只能生成单声道或立体声,无法准确定位声音源。
-
ImmerseDiffusion通过空间音频编解码器和潜在扩散模型实现声音的精准空间定位。
-
模型包含描述性条件模块和参数化条件模块,适用于不同应用场景。
-
评估结果显示,ImmerseDiffusion在生成质量和空间一致性方面表现出色。
-
研究团队提出了新的评估指标来衡量生成音频的质量和空间一致性。
-
ImmerseDiffusion的核心架构包括空间自编码器、条件块和扩散模型。
-
模型在多个数据集上训练,能够生成高质量的空间音频。
-
ImmerseDiffusion在虚拟现实、电影音效制作、教育和医疗等领域具有广泛应用前景。
-
研究人员计划进一步优化模型性能,提高生成音频的空间定位精度和环境适应性。
延伸解读
生成音频模型的技术突破
ImmerseDiffusion模型的推出标志着生成音频技术的一次重要进步。与传统的单声道或立体声模型相比,它能够实现更高质量的3D沉浸式音景,尤其在空间定位和环境模拟方面表现突出。这为虚拟现实和游戏开发提供了更为真实的音频体验,推动了沉浸式技术的发展。
应用场景的广泛性
ImmerseDiffusion不仅适用于游戏和电影音效制作,还在教育和医疗等领域展现出潜力。例如,在教育中,能够通过生动的音效增强学习体验,而在医疗中,精准的空间音频可用于模拟环境,帮助患者放松或进行治疗。这种多样化的应用前景使得该技术的商业价值显著提升。
模型优化的未来方向
尽管ImmerseDiffusion在生成音频的质量和空间一致性方面表现优异,但研究人员仍计划进一步优化其性能。这包括提高生成音频的空间定位精度和环境适应性。未来的改进将可能使其在更复杂的应用场景中表现得更加出色,值得关注其后续发展。
延伸问答
ImmerseDiffusion模型的主要功能是什么?
ImmerseDiffusion模型能够根据空间、时间和环境条件生成高质量的3D沉浸式音景。
ImmerseDiffusion与传统生成音频模型有什么不同?
与传统模型只能生成单声道或立体声不同,ImmerseDiffusion能够精准定位声音源并生成一阶Ambisonics音频。
ImmerseDiffusion的应用场景有哪些?
该模型适用于电影、游戏、虚拟现实、教育和医疗等多个领域。
ImmerseDiffusion是如何实现声音的空间定位的?
模型通过空间音频编解码器和潜在扩散模型实现声音的精准空间定位。
研究团队提出了哪些评估指标来衡量生成音频的质量?
评估指标包括环境声Fréchet音频距离、空间Kullback–Leibler散度和空间对比语言与音频预训练分数。
未来对ImmerseDiffusion模型有什么计划?
研究人员计划进一步优化模型性能,提高生成音频的空间定位精度和环境适应性。
