ImmerseDiffusion是一种新型生成音频模型,能够根据空间、时间和环境条件生成高质量的3D沉浸式音景。该模型专注于一阶Ambisonics音频,支持描述性和参数化模式,适用于电影和游戏等场景,表现出色,具有广泛应用前景。
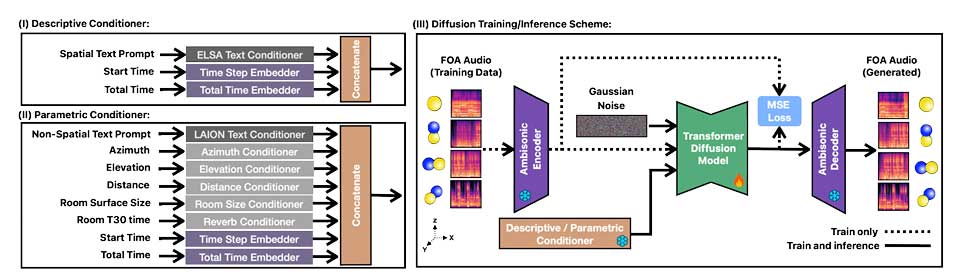
ImmerseDiffusion是一种生成音频模型,能够根据声音对象的空间、时间和环境条件生成3D沉浸式音景。该模型生成四通道的第一阶音频,结合空间音频编解码器和潜在扩散模型,支持文本提示和声学参数输入。评估结果表明,该模型在音频质量和空间一致性方面表现良好。
MAGNeT是一种生成音频的遮蔽生成序列建模方法,通过非自回归变换器预测遮蔽令牌跨度,并在推断过程中逐步构建输出序列。再评分方法和混合版本提高了生成音频的质量和速度。实证评估表明,MAGNeT与评估基线相当,但速度快7倍。消融研究和分析阐明了每个组成部分的重要性,并指出了自回归和非自回归建模之间的权衡。
完成下面两步后,将自动完成登录并继续当前操作。