
通义语音处理技术ClearerVoice-Studio
内容提要
随着语音技术的发展,语音质量受到重视。环境噪声和设备问题影响可懂度。通义实验室推出ClearerVoice-Studio,结合语音增强和分离功能,利用深度学习提升语音清晰度和降噪效果,以满足多种语音处理需求。
关键要点
-
语音质量受到环境噪声和设备问题的影响。
-
通义实验室推出ClearerVoice-Studio,集成语音增强和分离功能。
-
ClearerVoice-Studio利用深度学习提升语音清晰度和降噪效果。
-
该框架能够高效去除背景噪声,处理成高质量语音信号。
-
支持从复杂音频中分离目标语音,满足多种语音处理需求。
-
使用音视频结合的模型精确提取目标说话人的语音信号。
-
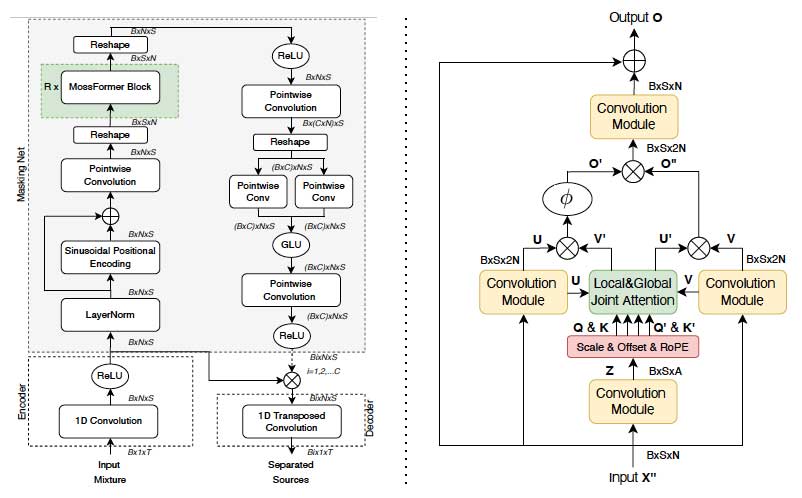
核心模型FRCRN在2022年取得优异成绩,展现语音增强能力。
-
MossFormer系列模型在语音分离任务中表现卓越,获得业内认可。
-
用户可通过简单操作上传语音文件,获得清晰音质和卓越降噪效果。
-
更多技术细节和模型评测结果可在ClearerVoice-Studio页面查看。
延伸解读
语音处理技术的应用场景
ClearerVoice-Studio的推出正值语音处理技术需求激增之际,尤其是在嘈杂环境中如地铁和餐厅等场所。用户可以通过该技术有效提升通话质量,减少背景噪声的干扰,适用于个人通话、会议录音等多种场景。
深度学习在语音处理中的优势
ClearerVoice-Studio利用深度学习算法,特别是FRCRN和MossFormer模型,显著提升了语音清晰度和降噪效果。这些技术的应用不仅提高了语音处理的效率,也为开发者提供了强大的工具,推动了语音技术的创新。
用户体验与操作简便性
ClearerVoice-Studio提供了简单易用的操作界面,用户只需上传包含噪声的语音文件,即可一键处理,快速获得清晰的音质。这种便捷性使得即使是非专业用户也能轻松享受高质量的语音处理服务。
延伸问答
ClearerVoice-Studio的主要功能是什么?
ClearerVoice-Studio集成了语音增强、语音分离和音视频说话人提取等功能。
如何使用ClearerVoice-Studio处理语音文件?
用户只需准备一段包含噪声的语音文件,上传至指定页面,一键处理后即可试听或下载处理结果。
ClearerVoice-Studio如何提升语音清晰度?
该技术利用深度学习算法,能够高效去除背景噪声,保留语音清晰度并最小化失真。
FRCRN模型在语音增强方面的表现如何?
FRCRN模型在2022年IEEE/INTER Speech DNS Challenge中取得整体第二的优异成绩,展现出卓越的语音增强能力。
MossFormer系列模型的特点是什么?
MossFormer系列模型在语音分离任务中表现卓越,首次超越SepFormer,获得业内广泛认可。
ClearerVoice-Studio适合哪些用户?
该平台旨在为开发者、研究者和企业提供强大的语音处理工具,助力创新应用落地。
