
从混乱到整洁:8个轻松的数据预处理Python技巧
内容提要
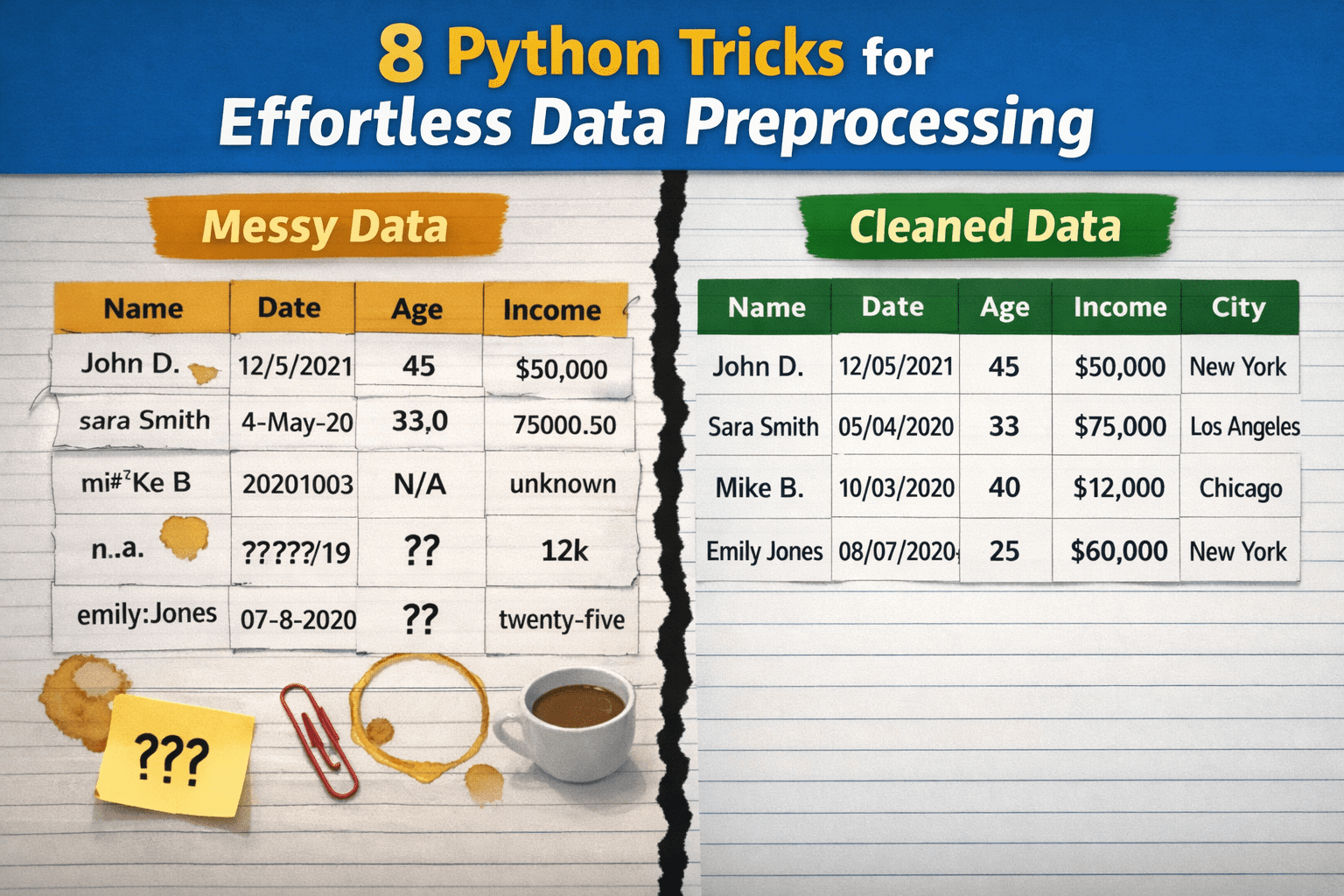
数据预处理在数据科学中至关重要,但常因复杂和耗时而被忽视。本文介绍了8个Python技巧,帮助用户轻松清理和标准化数据,包括列名规范化、去除空格、数值转换、处理缺失值、类别标准化、去重和剪裁异常值,从而提升数据处理效率。
关键要点
-
数据预处理在数据科学中非常重要,但常被忽视,原因是复杂和耗时。
-
本文介绍了8个Python技巧,帮助用户轻松清理和标准化数据。
-
技巧包括列名规范化、去除空格、数值转换、处理缺失值、类别标准化、去重和剪裁异常值。
-
第一步是规范化列名,确保一致性,避免后续任务中的错误。
-
第二步是去除字符串开头和结尾的空格,保持数据整洁。
-
第三步是安全地转换数值列,确保字符串格式的数值被正确转换为数字。
-
第四步是解析日期,使用errors='coerce'处理无效日期,避免程序崩溃。
-
第五步是使用统计默认值填补缺失值,而不是删除整行数据。
-
第六步是标准化类别,通过映射确保城市名称一致性。
-
第七步是灵活地去除重复项,确保每个用户只出现一次。
-
第八步是剪裁异常值,保持数据在合理范围内,而不是完全删除异常值。
-
这些技巧可以提升数据处理效率,使数据预处理管道更加高效和稳健。
延伸解读
数据预处理的重要性
数据预处理是数据科学的基础,直接影响后续分析和模型的准确性。忽视这一环节可能导致错误的结论和决策,因此掌握有效的预处理技巧至关重要。
处理缺失值的策略
处理缺失值时,使用统计方法填补比简单删除更为有效。通过填补缺失值,可以保留更多数据,避免信息损失,从而提高模型的稳定性和准确性。
异常值的处理方法
在数据清理过程中,剪裁异常值是一种有效的策略。与完全删除异常值相比,剪裁可以保留数据的完整性,同时减少因极端值导致的分析偏差。
标准化类别数据的必要性
在处理类别数据时,标准化名称可以避免因命名不一致导致的分析错误。通过映射和统一命名,可以提高数据的可用性和分析的准确性。
延伸问答
数据预处理的重要性是什么?
数据预处理在数据科学中至关重要,但常因复杂和耗时而被忽视。
有哪些Python技巧可以帮助数据清理?
本文介绍了8个Python技巧,包括列名规范化、去除空格、数值转换、处理缺失值等。
如何处理缺失值?
可以使用统计默认值填补缺失值,而不是删除整行数据。
如何安全地转换数值列?
可以使用pd.to_numeric函数,并设置errors='coerce'来安全转换数值列。
如何去除数据中的重复项?
可以使用drop_duplicates方法,指定subset参数来灵活去除重复项。
什么是剪裁异常值,如何实现?
剪裁异常值是通过设置极端值的上下限来保持数据在合理范围内,而不是完全删除它们。
