
在Heroku上构建AI搜索
内容提要
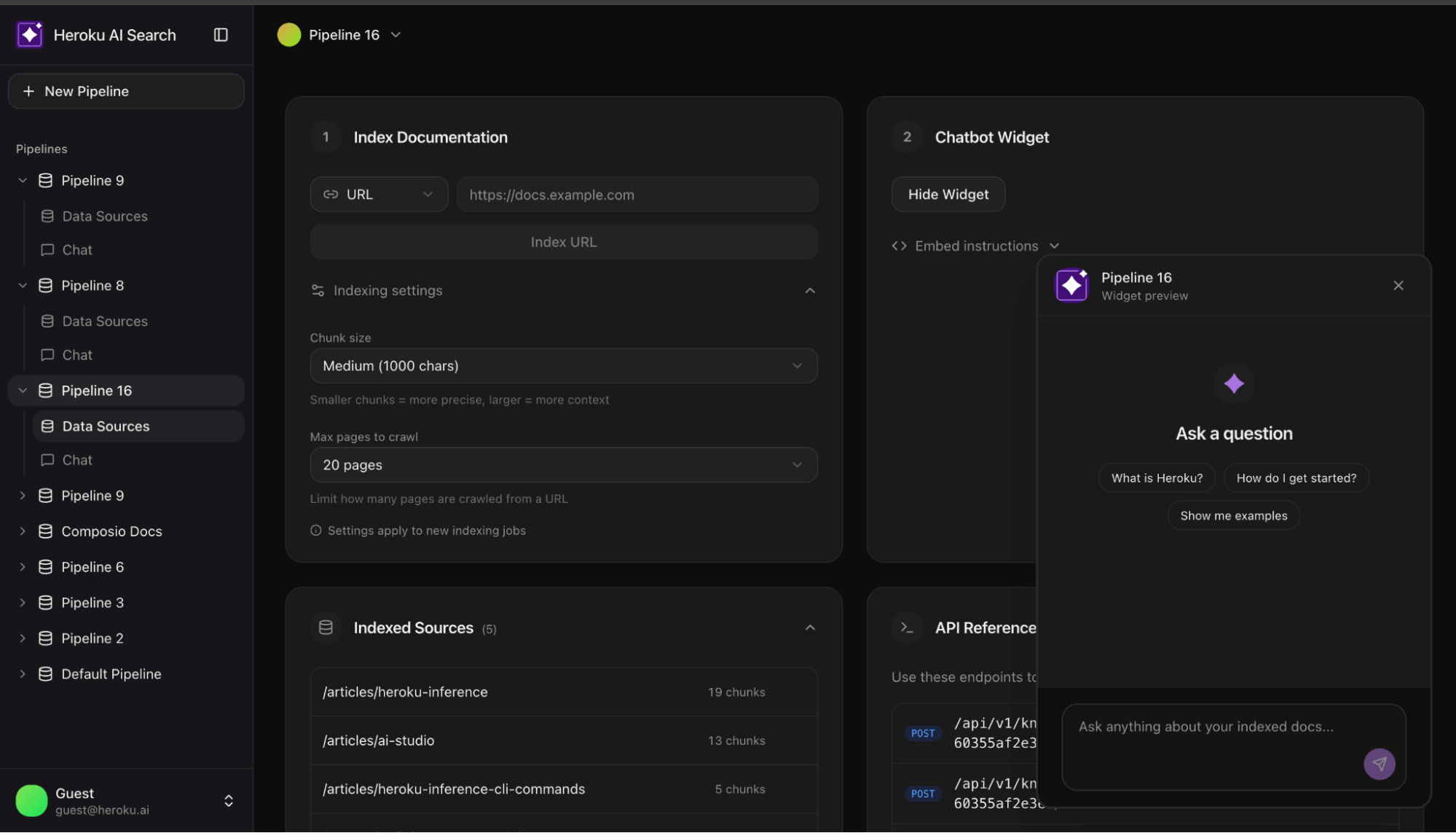
构建RAG系统时,向量搜索可能返回许多相似文档,但只有少数能回答用户问题。为提高准确性,需要引入二次排序模型来评估文档与查询的相关性。该架构利用Heroku服务,实现高效的文档检索和答案生成,确保搜索结果满足用户需求。
关键要点
-
构建RAG系统时,向量搜索可能返回许多相似文档,但只有少数能回答用户问题。
-
需要引入二次排序模型来评估文档与查询的相关性。
-
该架构利用Heroku服务,实现高效的文档检索和答案生成。
-
向量嵌入是高维空间中的坐标,语义接近性并不总是代表准确性。
-
系统由两个主要管道组成:索引管道和查询管道。
-
Heroku服务用于文本转向量、文档相关性评分和生成答案。
-
文档抓取需要避免提取无关内容,使用简单启发式检测垃圾内容。
-
文档按自然边界分块,以避免丢失意义。
-
检索分为两个阶段:向量搜索和语义重排序。
-
使用服务器推送事件(SSE)来流式传输进度,提升用户体验。
-
从演示到生产级RAG系统需要弥补相似性与相关性之间的差距。
延伸解读
向量搜索的局限性
虽然向量搜索能够快速找到语义相似的文档,但并不意味着这些文档一定能回答用户的问题。用户可能会收到大量相关性不高的结果,因此在构建RAG系统时,必须引入二次排序模型来提高结果的准确性。
文档抓取的挑战
在抓取文档时,常常会遇到无关内容的提取问题。使用简单的启发式方法可以有效识别垃圾内容,确保提取的文档更具相关性。这对于提高后续检索的效率至关重要。
用户体验的优化
在RAG系统中,使用服务器推送事件(SSE)可以提升用户体验,避免用户在等待过程中看到空白屏幕。通过实时反馈处理进度,用户能够更好地理解系统的工作状态,增强互动感。
延伸问答
如何提高向量搜索的准确性?
需要引入二次排序模型来评估文档与查询的相关性。
Heroku在构建AI搜索系统中起什么作用?
Heroku服务用于文本转向量、文档相关性评分和生成答案。
RAG系统的检索过程是怎样的?
检索分为两个阶段:向量搜索和语义重排序。
如何避免在文档抓取中提取无关内容?
使用简单启发式检测垃圾内容,避免提取过多导航链接。
RAG系统的架构主要由哪些部分组成?
系统由索引管道和查询管道两个主要部分组成。
如何实现文档的有效分块?
文档按自然边界分块,以避免丢失意义,通常在段落或句子断开处进行分块。
