
PaddleX 3.0-beta1 重磅升级,200+模型一站式全流程开发
内容提要
飞桨于2023年12月推出低代码开发工具PaddleX 3.0-beta1,集成200多个模型,支持一键调用和高性能推理。新版本提供多种部署方案,包括本地推理、服务化部署和端侧部署,兼容多种硬件,简化了模型训练和集成流程,降低了开发门槛,适合不同应用场景。
关键要点
-
飞桨于2023年12月推出低代码开发工具PaddleX 3.0-beta1,集成200多个模型。
-
新版本支持一键调用和高性能推理,简化模型训练和集成流程。
-
PaddleX提供多种部署方案,包括本地推理、服务化部署和端侧部署。
-
兼容多种硬件,如昆仑芯、昇腾、寒武纪、海光等,降低了开发门槛。
-
PaddleX支持命令行一键快速体验效果,方便用户使用和集成。
-
提供200多个模型的benchmark信息,帮助用户选择合适的模型进行微调训练。
-
高性能推理插件可显著提升模型推理速度,缩短推理时间。
-
服务化部署方案基于FastAPI框架,支持多种编程语言的调用。
-
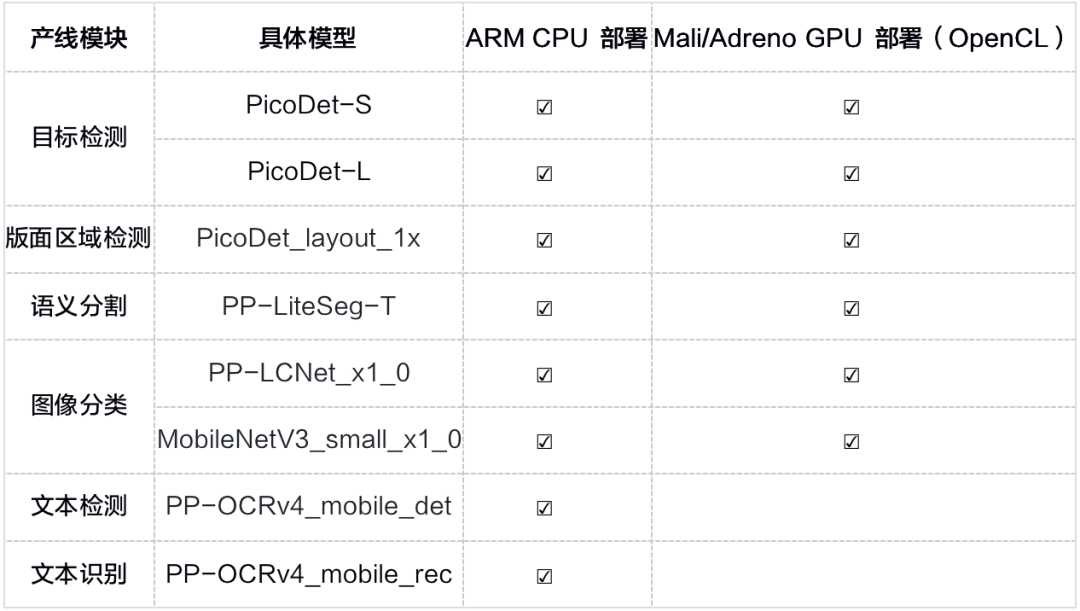
端侧部署支持Android demo,覆盖多条产线和模型,适配ARM CPU和GPU。
-
未来将继续适配更多模型,推动高性能和服务化部署的实施。
延伸解读
多模型支持的优势
PaddleX 3.0-beta1 集成了超过 200 个模型,涵盖文本图像分析、OCR 和目标检测等多个领域。这种多样性使得开发者能够根据具体需求快速选择合适的模型,降低了开发时间和成本。
灵活的部署方案
PaddleX 提供本地推理、服务化部署和端侧部署等多种方案,适应不同应用场景。特别是服务化部署基于 FastAPI 框架,支持多种编程语言,方便开发者在大规模应用中灵活调用模型。
高性能推理的实用性
新版本的高性能推理插件能够显著提升模型推理速度,最多可缩短 80% 的推理时间。这对于需要实时响应的应用场景尤为重要,开发者应关注如何有效利用这一功能来优化系统性能。
延伸问答
PaddleX 3.0-beta1有哪些主要功能?
PaddleX 3.0-beta1集成了200多个模型,支持一键调用、高性能推理和多种部署方案,包括本地推理、服务化部署和端侧部署。
PaddleX如何简化模型训练和集成流程?
PaddleX提供统一的Python API和命令行工具,用户可以通过简单的命令完成数据校验、模型训练、评估和推理,降低了开发门槛。
PaddleX支持哪些硬件?
PaddleX支持多种硬件,包括昆仑芯、昇腾、寒武纪和海光等,用户可以根据需要选择合适的硬件进行快速推理和二次开发。
如何在PaddleX中进行服务化部署?
用户可以通过PaddleX CLI一键将模型产线部署为服务,支持多种编程语言的调用,方便灵活地进行系统集成。
PaddleX的高性能推理插件有什么优势?
高性能推理插件可以显著提升模型推理速度,部分模型的推理时间可缩短80%以上,优化了模型推理及前后处理的性能。
PaddleX如何帮助用户选择合适的模型进行微调训练?
PaddleX提供200多个模型的benchmark信息,包括精度和推理速度等指标,帮助用户根据需求选择合适的模型。
