
KV Caching in LLMs: A Guide for Developers
💡
原文英文,约100词,阅读约需1分钟。
📝
内容提要
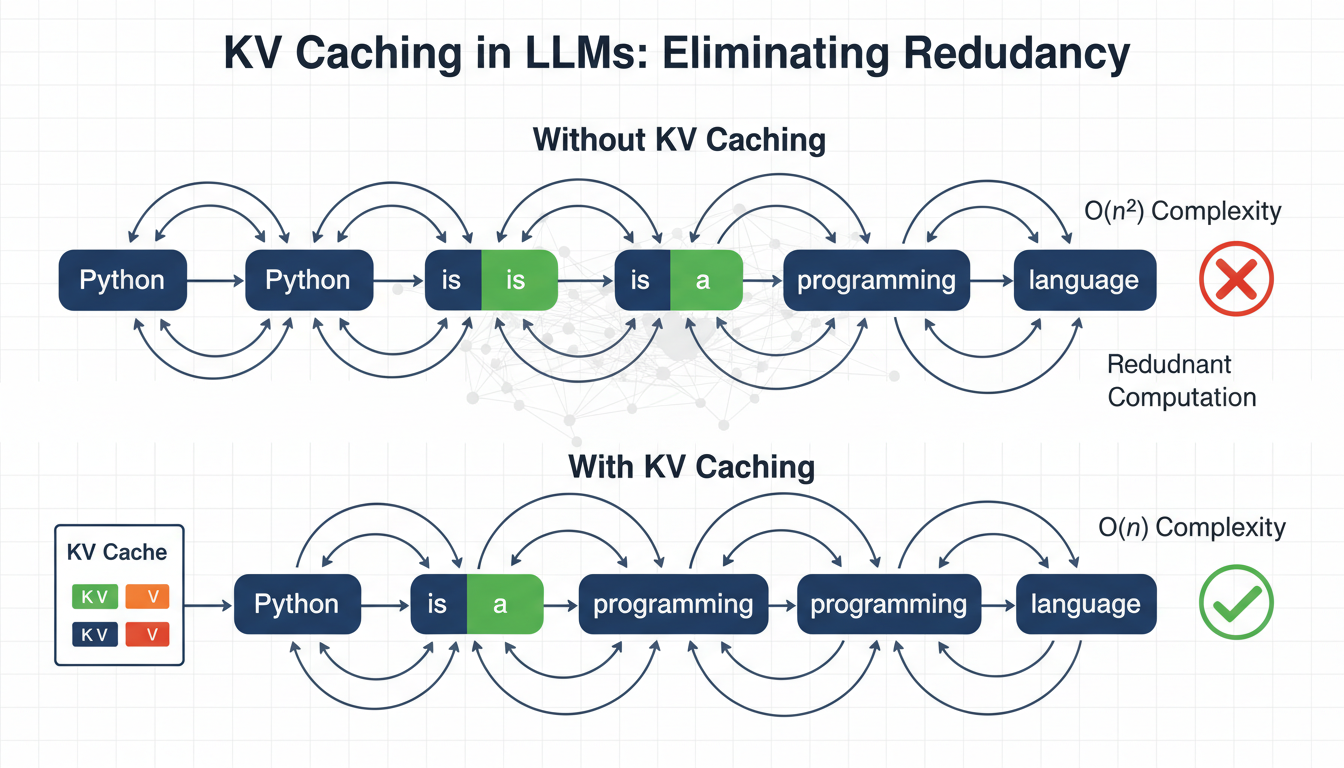
Language models generate text one token at a time, reprocessing the entire sequence at each step.
🏷️
标签
➡️
