
LLMs中的KV缓存:开发者指南
内容提要
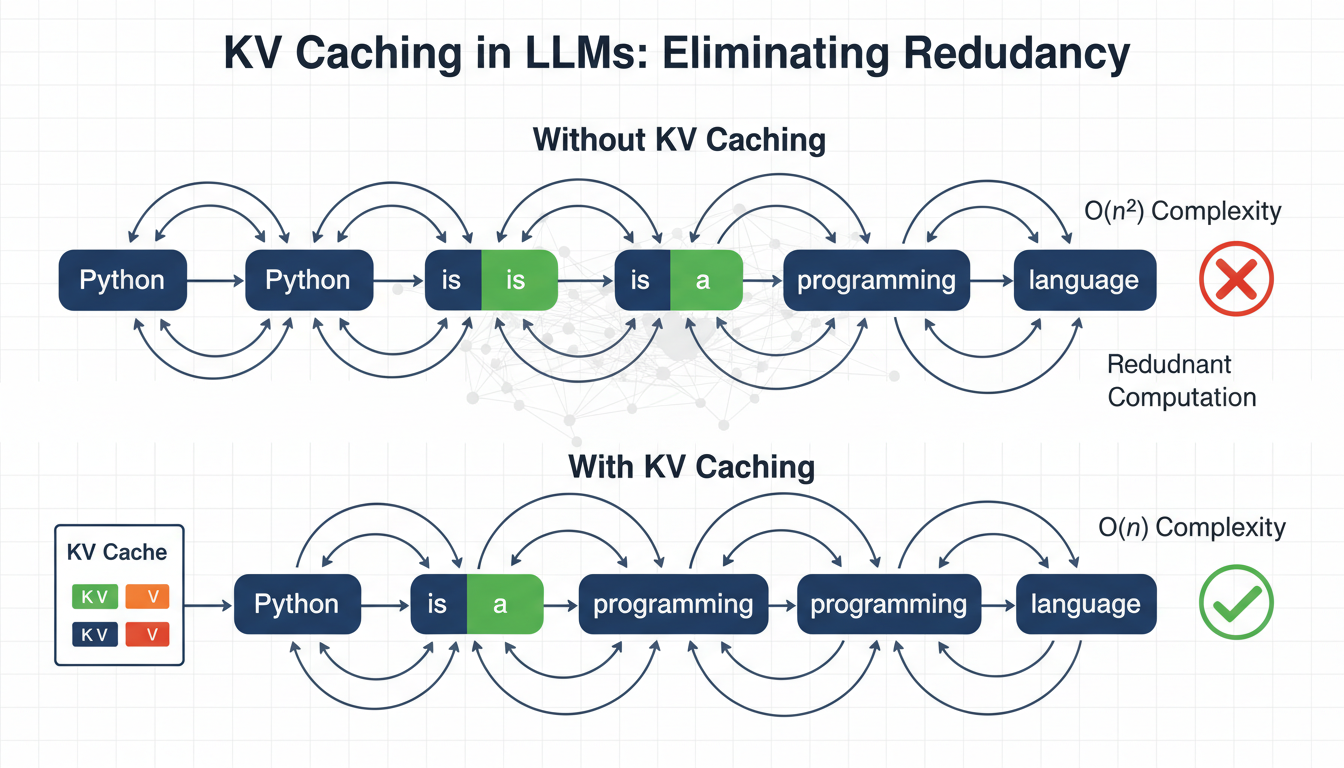
本文介绍了自回归变换器推理中键值(KV)缓存的作用,如何通过缓存已计算的键和值来消除冗余计算,从而显著提高生成速度,推理速度提升可达3-5倍。尽管内存使用增加,但在实际应用中,这种提升是值得的。理解KV缓存为进一步优化推理提供了基础。
关键要点
-
自回归生成的计算复杂度为O(n^2),每生成一个新token都需要重新处理所有之前的token。
-
KV缓存通过缓存已计算的键和值,消除了冗余计算,从而显著提高生成速度,推理速度提升可达3-5倍。
-
在推理过程中,只有当前token的查询(Q)会变化,而之前token的键(K)和值(V)可以被缓存并重用。
-
KV缓存的实现需要在注意力层中维护缓存状态,只有新token的K和V会被计算并添加到缓存中。
-
KV缓存解决了自回归文本生成中的一个基本限制,显著加快了大语言模型的推理速度,尽管内存使用增加,但在实际应用中这种提升是值得的。
延伸解读
KV缓存的内存开销
尽管KV缓存显著提高了推理速度,但其内存使用量也随之增加。开发者在实现时需权衡速度与内存消耗,尤其是在处理长文本时,缓存的大小可能会迅速增长,导致内存压力加大。
自回归生成的复杂性
自回归生成的计算复杂度为O(n^2),这意味着随着生成的token数量增加,计算量会急剧上升。KV缓存通过消除冗余计算,解决了这一基本限制,使得生成过程更加高效。
实现KV缓存的注意事项
在实现KV缓存时,确保在每次生成请求之间清空缓存是至关重要的。未能清空缓存可能导致上下文污染,影响生成结果的准确性。开发者应在每次生成前调用重置缓存的函数。
延伸问答
KV缓存如何提高自回归生成的速度?
KV缓存通过缓存已计算的键和值,消除了冗余计算,从而使推理速度提升可达3-5倍。
自回归生成的计算复杂度是什么?
自回归生成的计算复杂度为O(n^2),每生成一个新token都需要重新处理所有之前的token。
KV缓存的实现需要注意哪些方面?
KV缓存的实现需要在注意力层中维护缓存状态,只有新token的K和V会被计算并添加到缓存中。
KV缓存的内存使用情况如何?
尽管KV缓存会增加内存使用,但在实际应用中,这种提升是值得的。
KV缓存如何解决自回归文本生成的限制?
KV缓存通过缓存之前token的键和值,避免了重复计算,从而显著加快了推理速度。
KV缓存的使用对生成文本的影响是什么?
KV缓存使得生成文本的过程更高效,计算量保持恒定,推理速度显著提升。
