

梁文锋署名的DSpark,看懂这10个点就够了!
量子位
·

DeepSeek又变强了:发布DSpark框架 推理速度提升超60%
TechWeb 全站精华
·
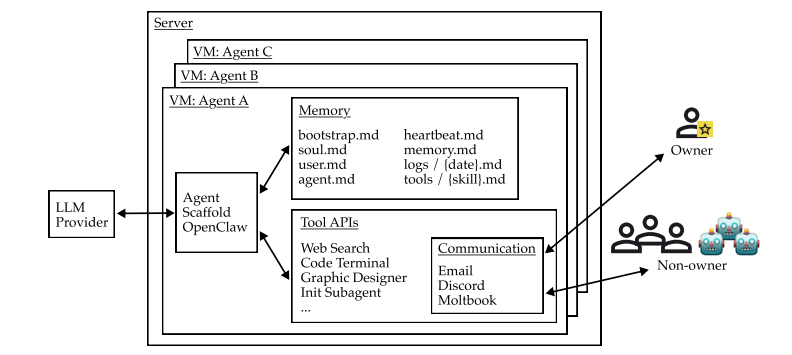
JetBrains开源Mellum2,以超越Claude Code的局限
The New Stack
·

大语言模型速度基准:指标与基础设施指南
Redis Blog
·

一分钟读论文:《用扩散语言模型统一多模态理解与生成》
Micropaper
·

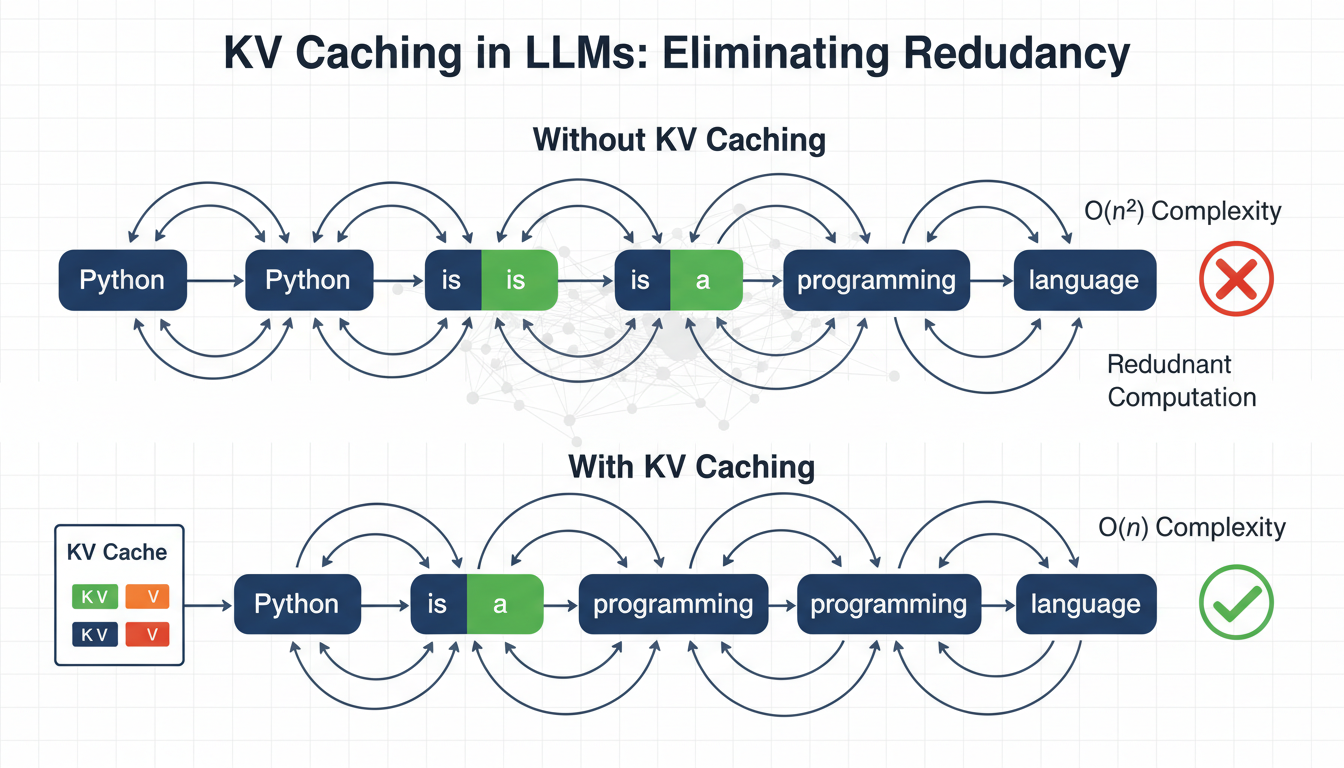
LLMs中的KV缓存:开发者指南
MachineLearningMastery.com
·

