

理解 KV Cache:Attention、P/D 分离与 vLLM 的页式显存管理
Steins;Lab
·


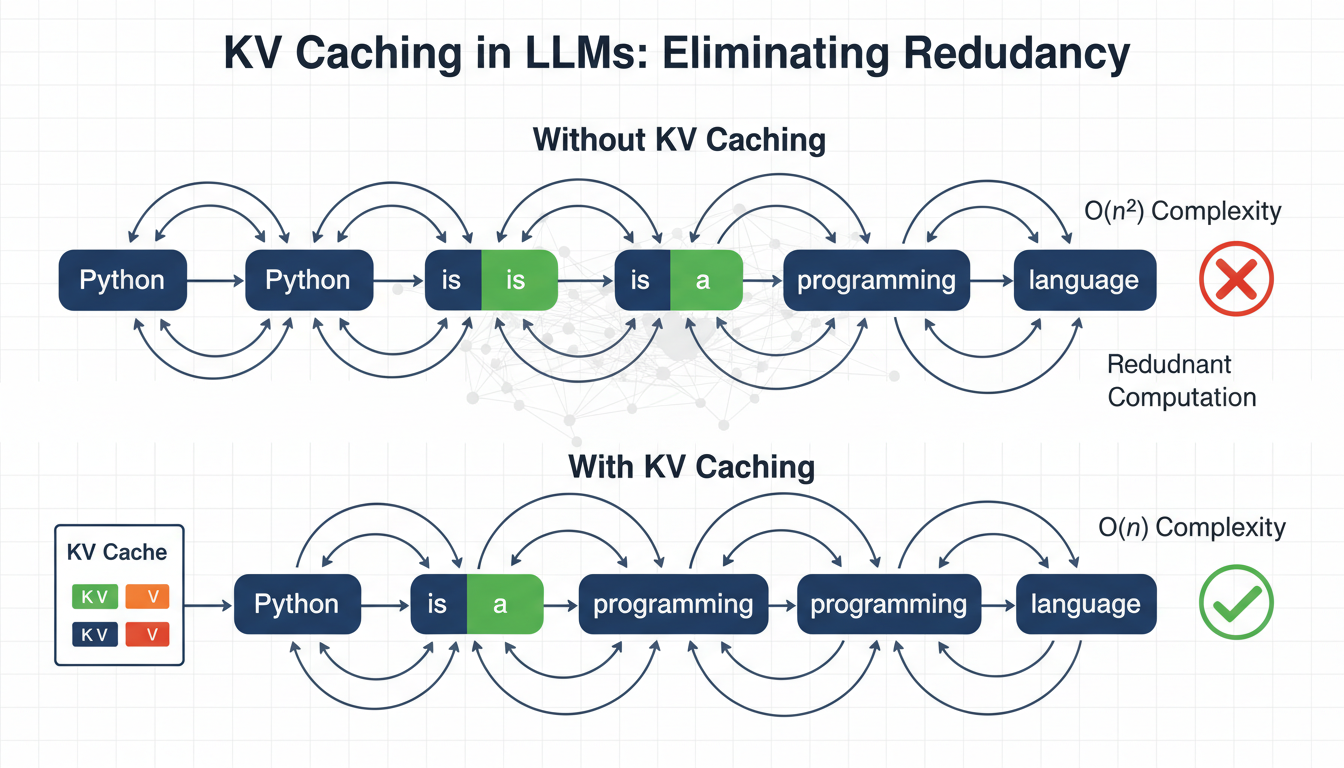
LLMs中的KV缓存:开发者指南
MachineLearningMastery.com
·
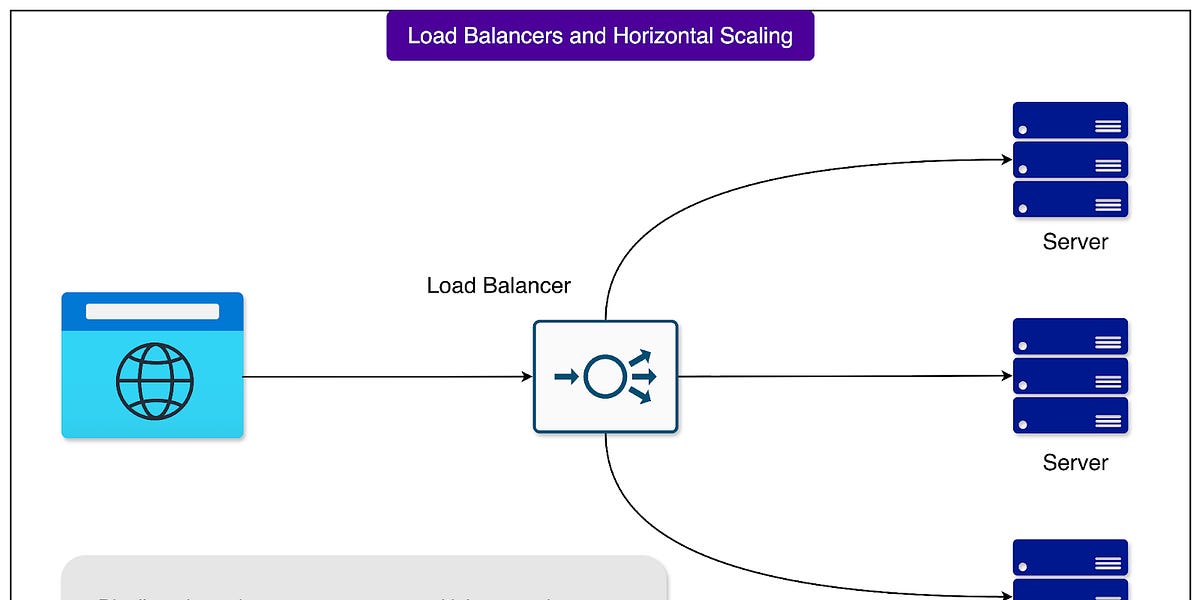
记忆问题:为什么大型语言模型有时会忘记你的对话
ByteByteGo Newsletter
·

SMUGGLER:亚二次方多尺度统一生成门控语言编码器-表示
DEV Community
·

自动微分再探
Lei Mao's Log Book
·

Swin变换器
DEV Community
·


