
用上这个Skill,你的Claude Code/Codex 将会比别人快5倍 -- 用分布式思维驯服AI任务编排
内容提要
文章探讨了如何高效利用AI处理复杂任务,提出将大任务拆分为小任务并行执行的思路。通过设计分布式任务编排系统,用户能够更好地管理AI输出,避免信息混乱,提高效率。核心在于将AI视为项目经理,合理分配任务,实现快速、结构化的结果输出。
关键要点
-
文章探讨如何高效利用AI处理复杂任务。
-
提出将大任务拆分为小任务并行执行的思路。
-
设计分布式任务编排系统以管理AI输出,避免信息混乱。
-
将AI视为项目经理,合理分配任务,实现快速、结构化的结果输出。
-
传统AI使用方式存在复杂性集中在AI和用户身上的问题。
-
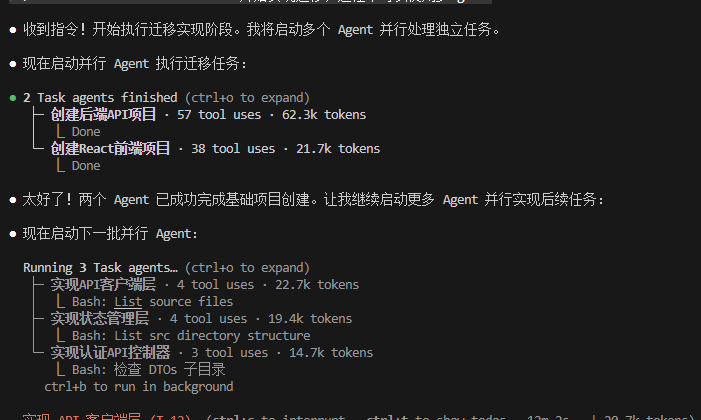
新方法通过Orchestrator将复杂任务拆分成原子任务并行执行。
-
强调任务的单一职责、独立可执行性、可验证性和支持重试。
-
使用状态管理系统来维护任务状态,确保任务执行的可追踪性。
-
并行执行需遵循依赖关系,采用拓扑排序和批次执行算法。
-
聚合结果时需去重、排序和提炼,生成完整报告。
-
处理任务依赖关系有三种模式:串行依赖、完全并行和DAG依赖。
-
设计容错机制以应对AI任务执行中的各种错误。
-
通过实际案例展示分布式任务编排的效率提升。
-
总结了任务粒度、依赖定义、并发数和聚合成本等常见问题。
-
强调将复杂问题分解为简单问题的思维模式的普适价值。
-
未来希望实现更智能的任务分解和动态负载均衡。
延伸解读
分布式思维的优势
文章强调了将复杂任务拆分为小任务并行处理的重要性。这种分布式思维不仅提高了效率,还能减少信息混乱。通过合理的任务分配,AI可以更像项目经理,确保每个任务独立执行,从而提升整体工作流的灵活性和响应速度。
任务依赖关系的管理
处理任务依赖关系是实现高效并行执行的关键。文章提到三种依赖模式:串行依赖、完全并行和DAG依赖。理解这些模式有助于用户在设计任务时,合理安排执行顺序,避免因依赖关系不清导致的执行失败。
容错机制的重要性
在分布式任务编排中,容错机制至关重要。文章介绍了三层容错设计,包括自动重试、故障隔离和状态持久化。这些机制确保了即使在出现错误时,系统也能保持稳定运行,减少因单个任务失败而导致的整体流程中断。
延伸问答
如何高效利用AI处理复杂任务?
可以将大任务拆分为多个小任务并行执行,通过设计分布式任务编排系统来管理AI输出,避免信息混乱。
分布式任务编排系统的核心思想是什么?
核心思想是将AI视为项目经理,合理分配任务给多个专项小组,从而实现快速、结构化的结果输出。
在AI任务执行中如何处理任务依赖关系?
可以采用串行依赖、完全并行和DAG依赖三种模式,确保任务按照依赖关系正确执行。
如何确保AI任务执行的可追踪性?
使用状态管理系统来维护任务状态,确保每个任务的执行状态可追踪,并记录在文件中。
分布式任务编排系统如何提高执行效率?
通过并行执行多个原子任务,减少整体执行时间,并利用状态持久化和故障隔离机制提高鲁棒性。
在设计分布式任务编排时需要注意哪些常见问题?
需要注意任务粒度、依赖定义、并发数和聚合成本等问题,以避免调度开销过高或输出混乱。
