
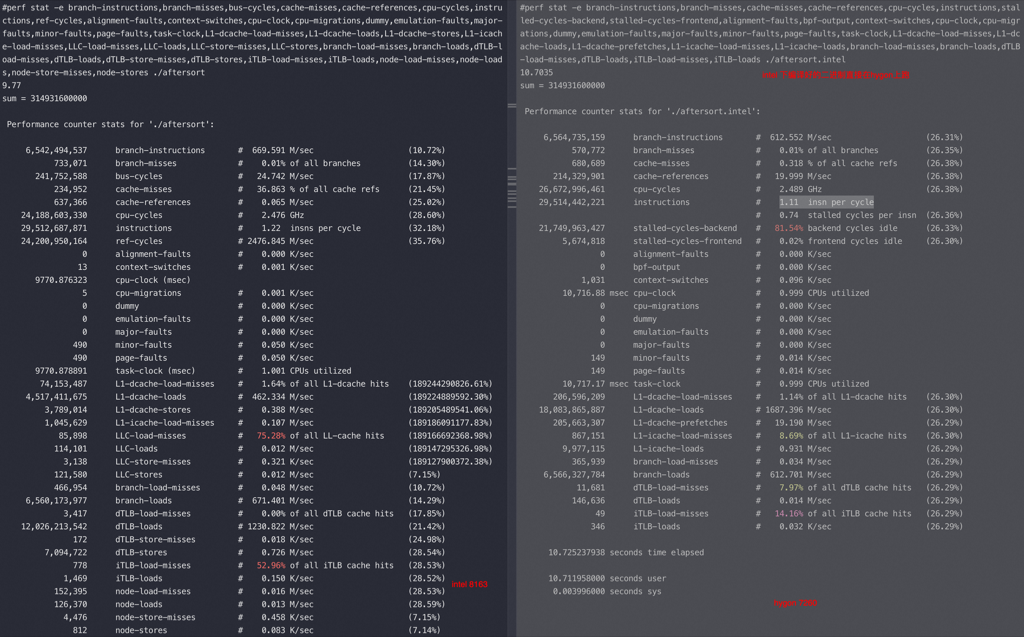
比较不同CPU下的分支预测
原文中文,约40300字,阅读约需96分钟。
📝
内容提要
本文比较了不同CPU下的分支预测性能,通过测试验证了其对性能的影响。在x86和aarch64架构下,对比了Intel x86 8163、ARM鲲鹏920、M710和Hygon 7260的差异性。开启gcc O3优化后,所有CPU的性能有所提升。
🎯
关键要点
-
本文比较了不同CPU下的分支预测性能,验证了其对性能的影响。
-
在x86和aarch64架构下,比较了Intel x86 8163、ARM鲲鹏920、M710和Hygon 7260的差异。
-
开启gcc O3优化后,所有CPU的性能有所提升。
-
通过测试代码验证branch load miss差异及其带来的性能差异。
-
不同CPU的分支预测性能差异主要体现在branch-load-misses和branch-misses上。
-
排序后的代码使得CPU流水线更容易预测,导致更高的IPC。
-
M710在排序后的性能优于鲲鹏920,且IPC提升显著。
-
Hygon 7260在排序前的性能优于Intel 8163,但排序后略慢于Intel。
-
使用-O3优化后,所有CPU的性能提升明显,尤其是branch-load-misses显著减少。
-
分支预测原理中,__builtin_expect函数可以帮助编译器优化分支预测。
-
总结中列出了不同CPU在排序前后的性能对比数据,显示了排序对性能的影响。
🏷️
