

大疆便携储能电源获TÜV南德颁发S级紧凑型及性能稳定认证证书
全球TMT-美通国际
·
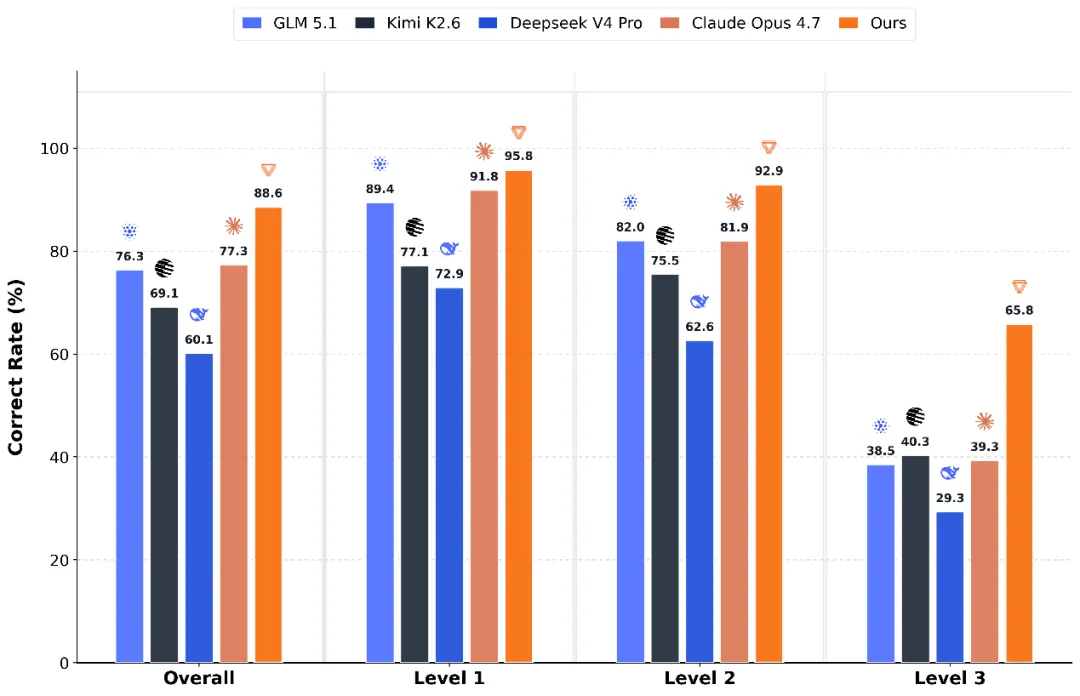

这家AI代理初创公司放弃了Anthropic,转而选择DeepSeek,并表示节省了数百万美元
The New Stack
·

使用virtbench对KubeVirt性能进行基准测试
Cloud Native Computing Foundation
·

华为自研HBM性能翻倍!昇腾950DT芯片8月提前问世,DeepSeek将优先部署
TechWeb 全站精华
·

史上最强游戏掌机来了!性能堪比 PS5,但……
爱范儿
·

谷歌Gemma 4 12B的性能几乎与26B基准相当——并可在您的笔记本电脑上运行
The New Stack
·

Valkey 为什么这么快?盘点 Valkey 中提升性能的黑科技
亚马逊AWS官方博客
·


AI 范式雷达:《高质量合成数据让多步工具调用性能飙升 10%》
Micropaper
·

GitHub如何计划重新赢回开发者
The New Stack
·


英伟达与联发科联手打造RTX Spark超级芯片:手机能效与PC性能的跨界融合
TechWeb 全站精华
·

LivePerson如何通过基准测试优化GCP上的Logstash和Kafka性能
Elastic Blog - Elasticsearch, Kibana, and ELK Stack
·
